
Kubeflow
compute-pipelines
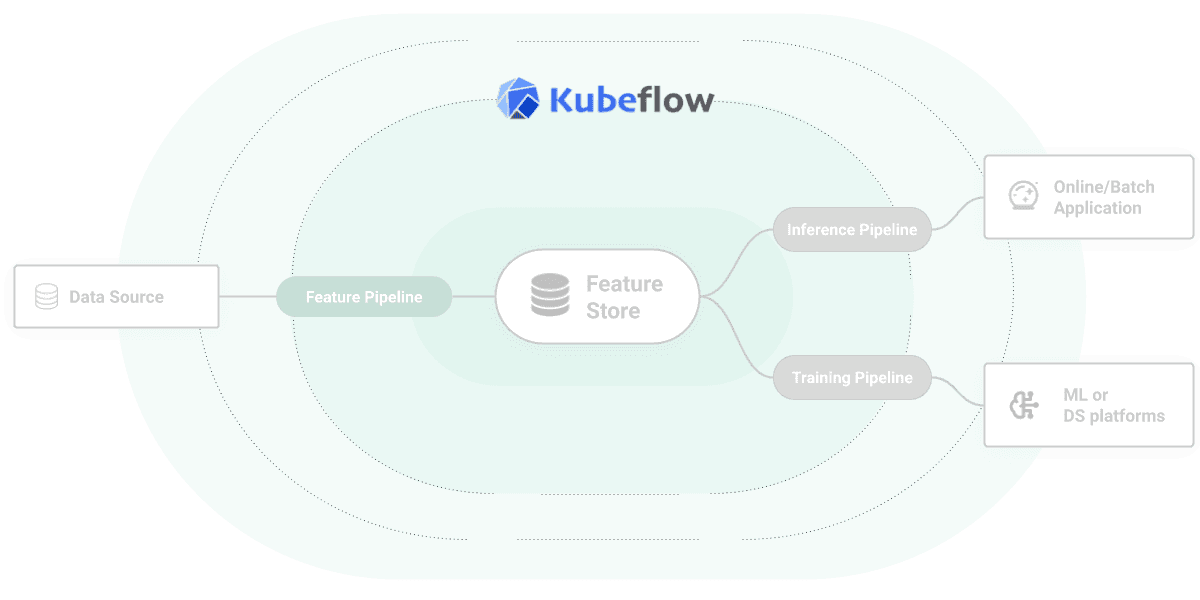
Kubeflow can be used as the orchestration engine for all your machine learning pipelines (feature pipelines, training pipelines, and batch inference pipelines). These pipelines write/read their state to/from Hopsworks. Jupyter Notebooks can use Hopsworks to discover and use features to create training data.