The AI Lakehouse
Extend your lakehouse for AI with real-time feature serving, Python-native performance, and LLM support. Build batch, real-time, and LLM AI systems on open standards.
The Lakehouse Gap
Nearly half of all models (48%) still fail to make it to production. The disconnect between MLOps platforms and the Lakehouse is a key reason why.
No Real-Time Data
The Lakehouse has too high latency to power real-time AI systems. You can't build the next TikTok on Databricks today.
Python is 2nd Class
JDBC/ODBC APIs result in poor read throughput. Databricks serverless doesn't even support installing Python libraries.
Disconnected from LLMs
No clear architecture for how Lakehouse data can power RAG or create instruction datasets for fine-tuning.
The AI Lakehouse solution: Real-time streaming data, Python-native query engine with 9-45X better performance, and native LLM support for RAG and fine-tuning - all on open table formats.
AI Lakehouse Architecture
A modular stack that separates storage, transactions, compute, and catalog - extended with AI pipelines, AI query engine, and infrastructural services for ML.
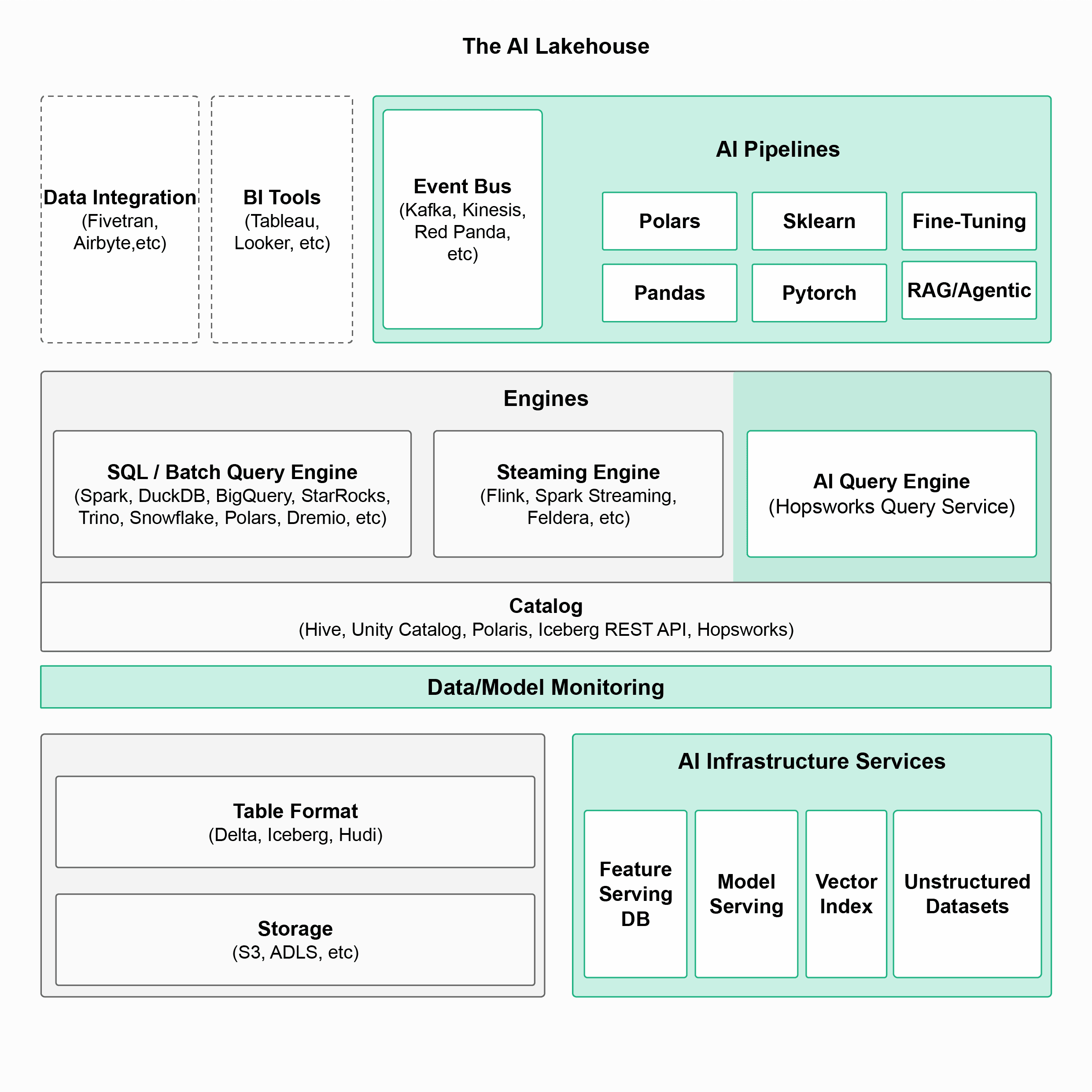
Open Table Formats
Native support for Apache Iceberg, Delta Lake, and Apache Hudi. No migrations, no vendor lock-in.
Real-Time AI
Sub-second feature freshness for real-time AI systems. Build TikTok-style recommenders.
Python Native
9-45X faster than competitors. Arrow-native transfer protocol for Pandas/Polars clients.
LLM Support
RAG with Lakehouse data, instruction datasets for fine-tuning, vector search integration.
Time Travel
Reproducible training data based on ingestion timestamps. Audit-ready data lineage.
Enterprise Security
Fine-grained access control, encryption at rest, SOC 2 and ISO 27001 compliant.
Python Performance That Changes Everything
The Hopsworks Query Service provides Arrow-native transfer from Lakehouse tables to Python clients. Benchmarked and published at SIGMOD 2024.
9X
faster
vs Databricks
Feature Group reads
25X
faster
vs Sagemaker
Point-in-time JOINs
45X
faster
vs Vertex
Training data creation
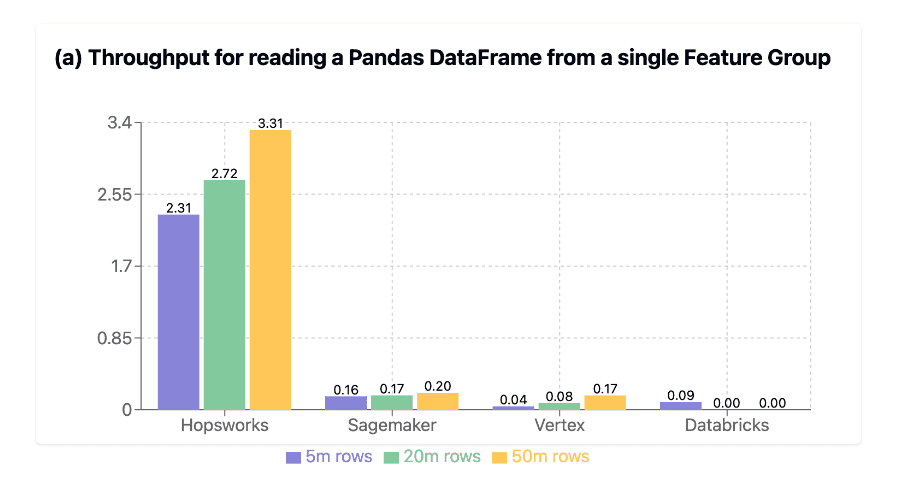
Feature Group read throughput comparison
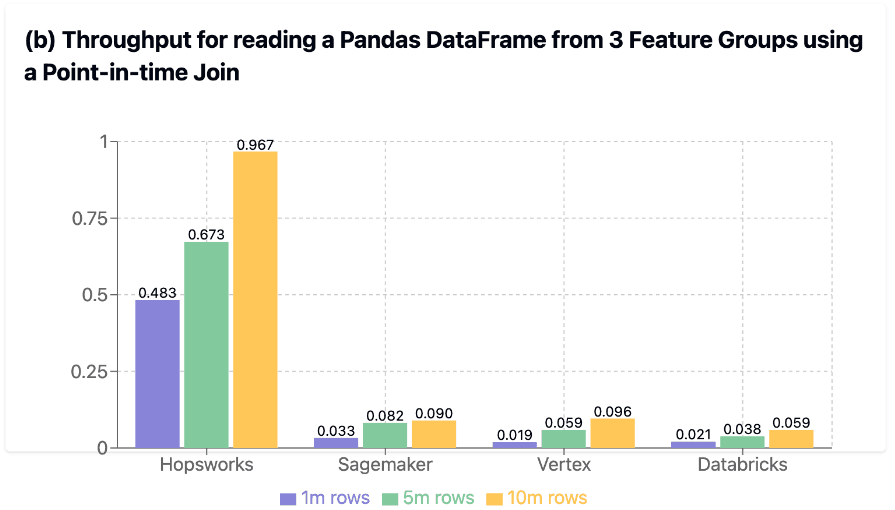
Point-in-time JOIN performance comparison
Build TikTok-Style Recommenders
ByteDance's real-time recommender for TikTok processes user interactions and adjusts recommendations within seconds. It's built on an exabyte-sized Iceberg Lakehouse with real-time streaming extensions.
The AI Lakehouse provides streaming feature pipelines connected to a low-latency feature serving database. The Lakehouse stores historical data for training - it's not a message broker for your feature database.
Sub-second feature freshness
Snowflake schema for feature reuse
Same code for batch & real-time features
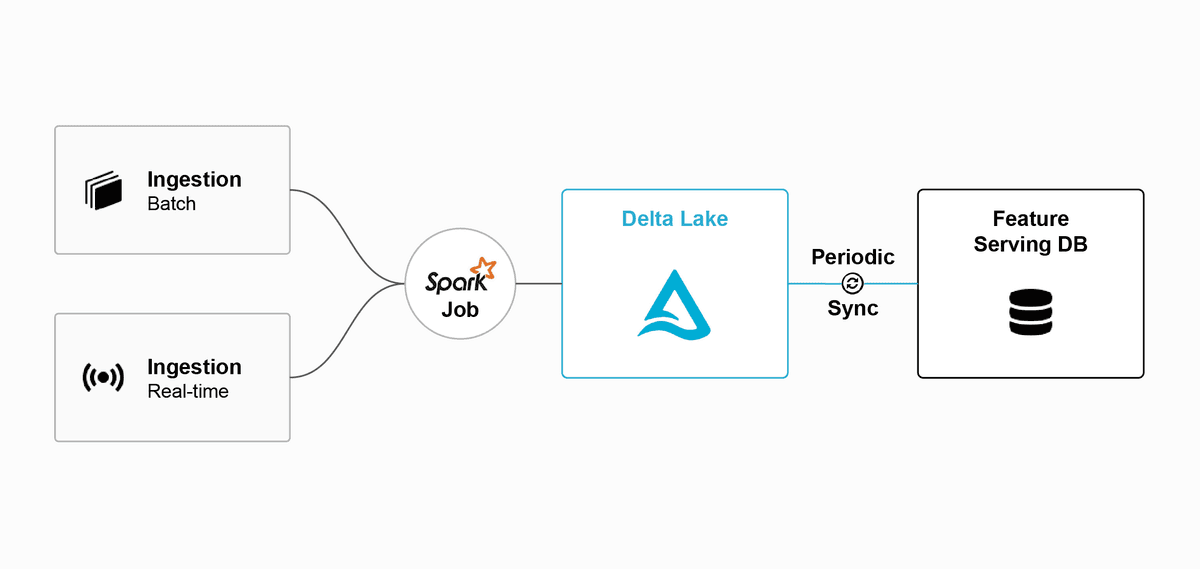
Real-time AI systems need streaming feature pipelines connected to a low-latency feature serving database - not the Lakehouse.
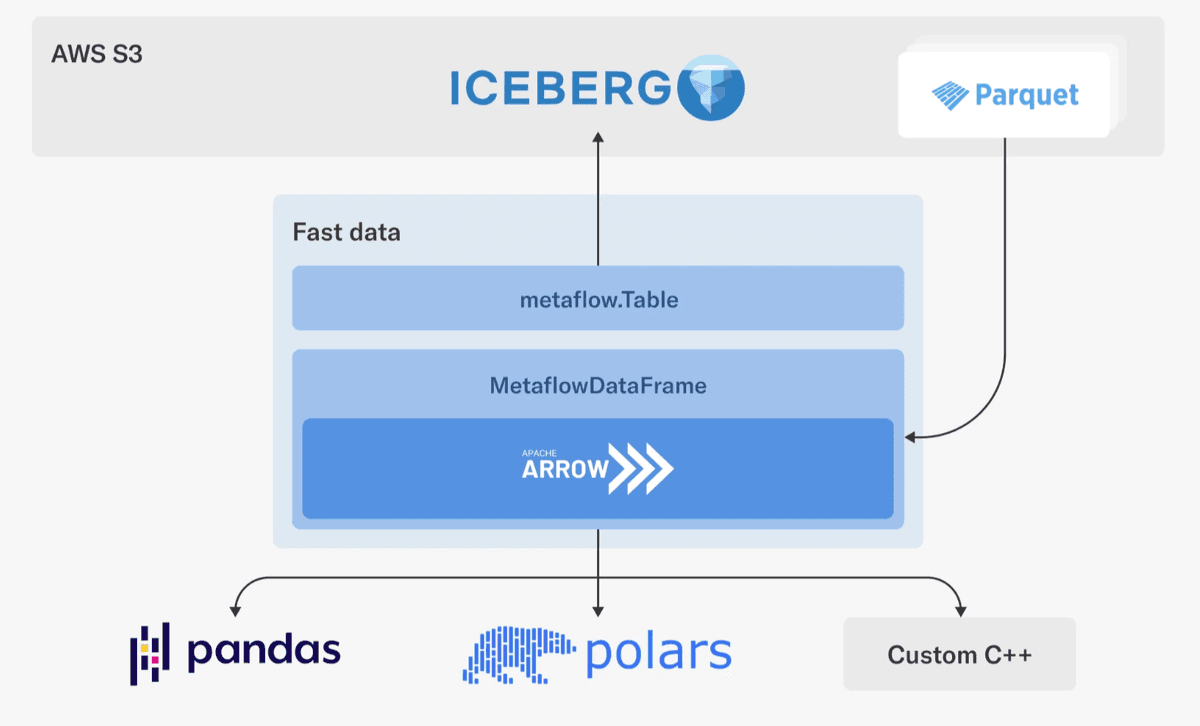
Netflix fixed the Python performance bottleneck with an Arrow-native transfer protocol. Hopsworks does the same.
Python as a First-Class Citizen
Netflix needed higher Python performance for their Data Scientists. They developed an Arrow-native transfer protocol from Iceberg tables to Pandas/Polars clients.
Hopsworks Query Service does the same - and more. Temporal JOINs, pushdown filters, credential vending, and reproducible training data creation.
“We want to support last-mile data processing in Python, addressing use cases such as feature transformations, batch inference, and training.”
- Netflix Engineering Blog
Lakehouse Data for LLMs
Your most valuable enterprise data is in the Lakehouse. It should be available for RAG and fine-tuning - not siloed away from your LLM applications.
The AI Lakehouse enables function calling to query Lakehouse data in LLM prompts, vector search integration for RAG, and instruction dataset creation for fine-tuning - all while maintaining data governance.
RAG with governed Lakehouse data
Instruction datasets for fine-tuning
Data security & governance preserved
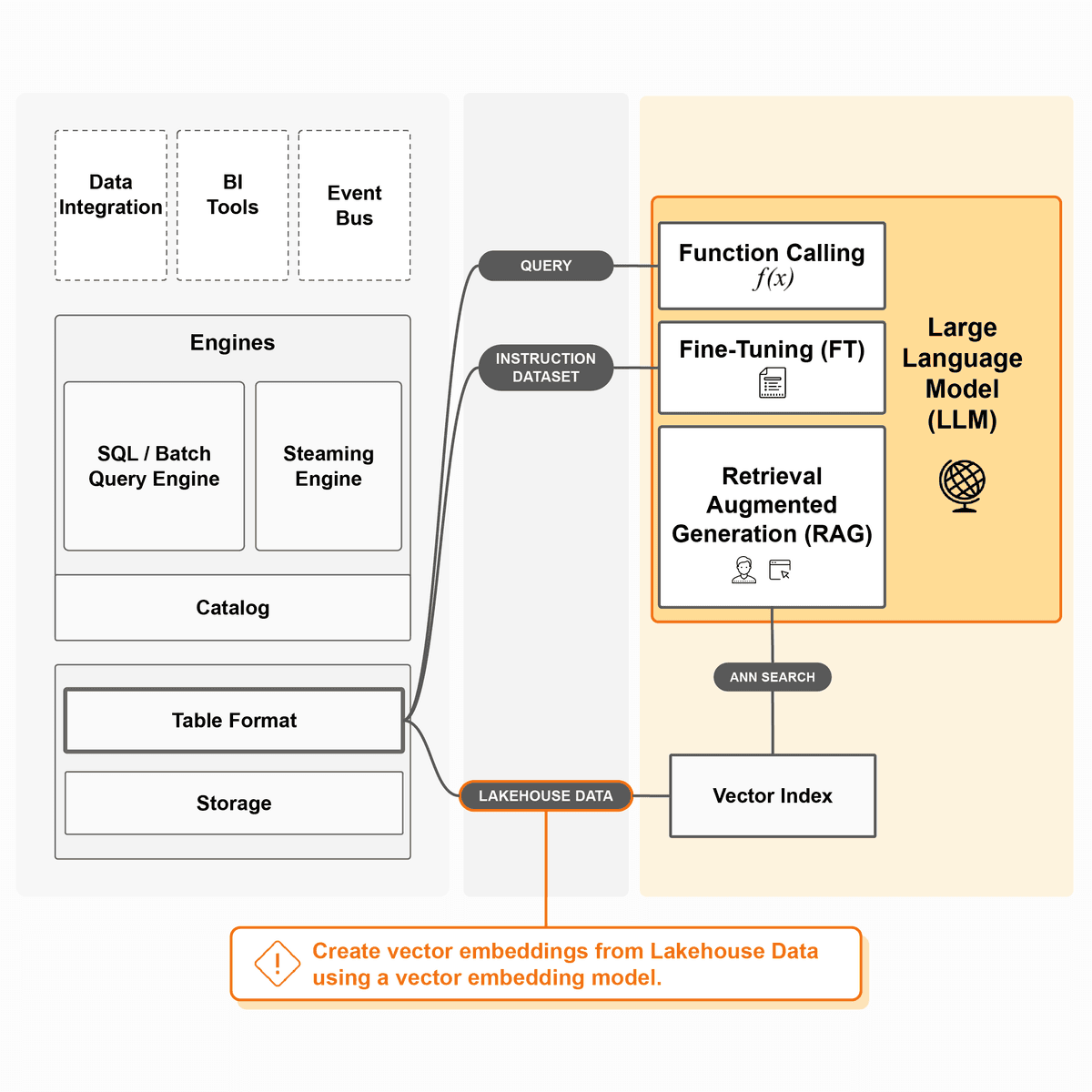
Architecture for using Lakehouse data to power RAG and create instruction datasets for fine-tuning.
Open Standards, No Lock-In
Work with the tools you already use. The AI Lakehouse is built on open table formats and integrates with the entire modern data stack.
Native Open Table Format Support
Apache Iceberg
Open table format for huge analytic datasets
Delta Lake
Open-source storage framework by Databricks
Apache Hudi
Streaming data lake platform
Compute & Query Engines








FTI Pipeline Architecture
A unified framework for building real-time, batch, and LLM AI systems. Feature pipelines, Training pipelines, and Inference pipelines - composed together by AI Lakehouse infrastructure.
Feature Pipelines
Transform input data from any source into features. Output to Lakehouse tables and feature serving tables for real-time systems.
Training Pipelines
Read feature data from Lakehouse tables with point-in-time correctness. Output trained models to the model registry.
Inference Pipelines
Batch, streaming, or real-time. Read features and models, output predictions. Same architecture for all inference modes.
Build AI Systems on Open Standards
The AI Lakehouse is the starting point for the next generation of AI platforms. Real-time, batch, and LLM systems - all on your data, your infrastructure.