MLOps That Actually Works
48% of models never make it to production. The FTI pipeline architecture changes that - a unified framework for batch, real-time, and LLM systems.
The 10 Fallacies of MLOps
MLOps fallacies slow AI deployment and add complexity. These bad assumptions cause AI systems to never make it to production.
One ML Pipeline
You cannot run any AI system as a single pipeline. Real-time systems need separate training and inference pipelines.
DevOps is Enough
MLOps is more than DevOps. You need to version and test data, not just code.
Start with Experiment Tracking
Experiment tracking is premature optimization. Focus on your minimal viable AI system first.
Model Signature = Deployment API
The deployment API is not the model signature. They should be decoupled for maintainability.
The Solution: FTI Architecture
Decompose your AI system into Feature, Training, and Inference pipelines. Clear interfaces, modular development, and the same architecture for batch, real-time, and LLMs.
The FTI Pipeline Architecture
A mental map for MLOps that has enabled hundreds of developers to build maintainable ML systems. Students go from zero to working ML system in 2 weeks.
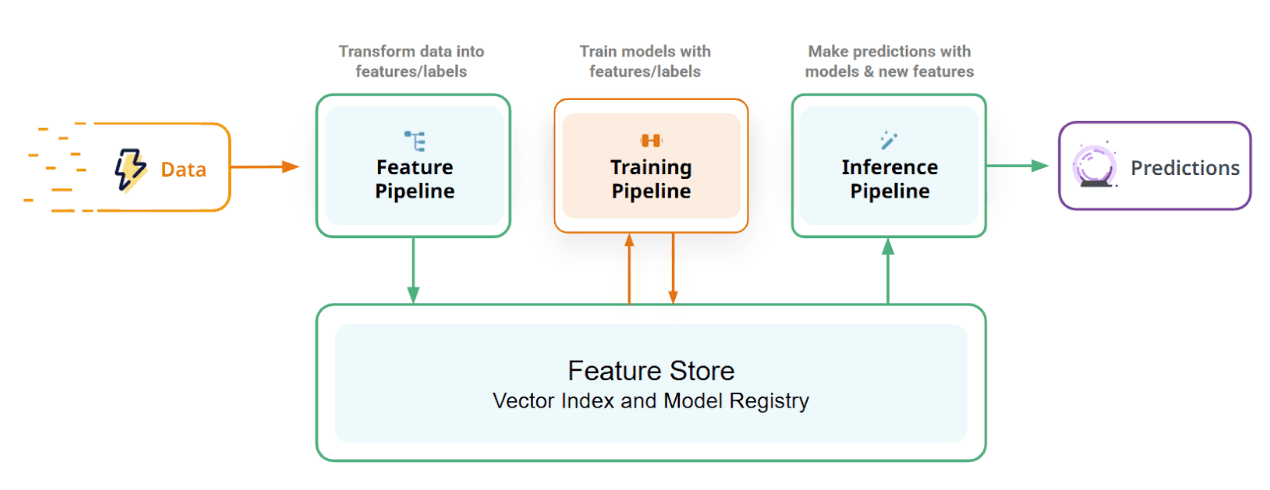
Feature/Training/Inference pipelines connected via Feature Store and Model Registry
Feature Pipelines
Transform raw data into features. Batch or streaming. Output to feature store.
Training Pipelines
Read features, train models, output to model registry. On-demand or scheduled.
Inference Pipelines
Take models and features, output predictions. Batch, real-time, or agents.
Choose Your Own Stack
FTI pipelines are an open architecture. Use Python, Java, or SQL. Pick the best framework for each pipeline based on your requirements.
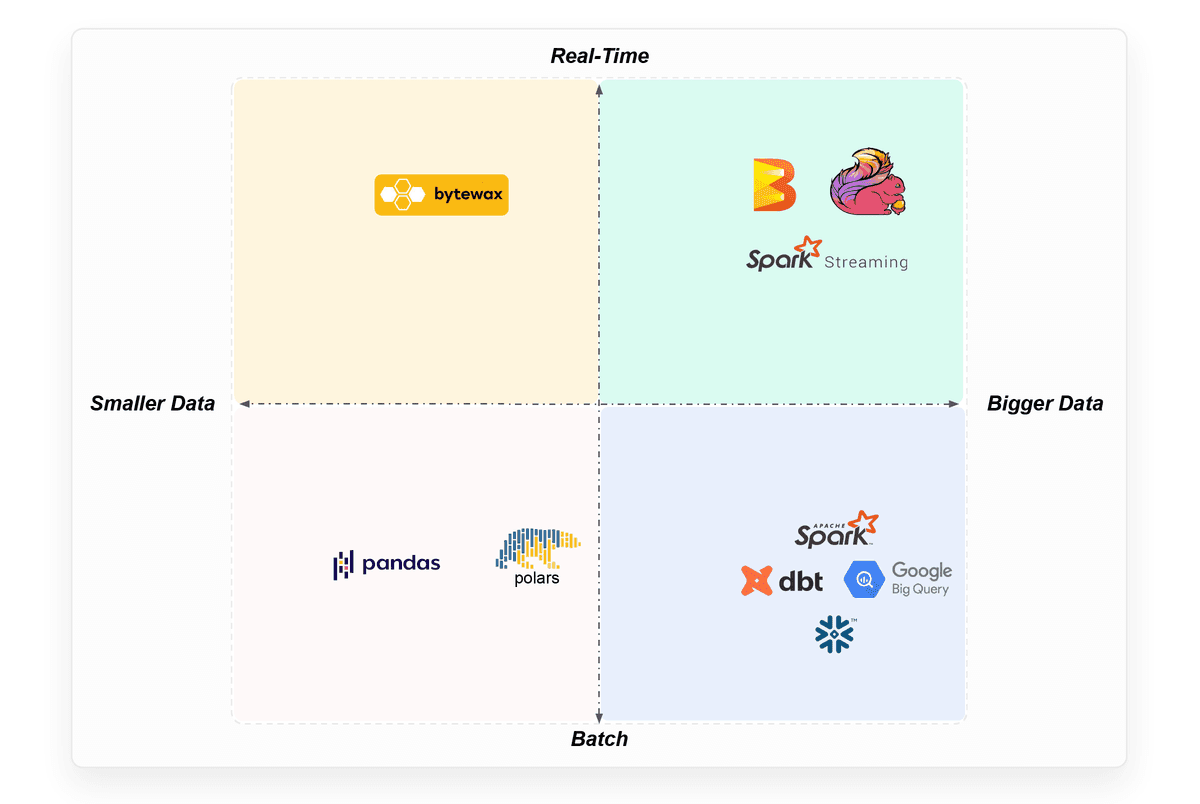
Pick the best framework for your feature pipeline: Pandas for small data, PySpark for big data, Flink for streaming.
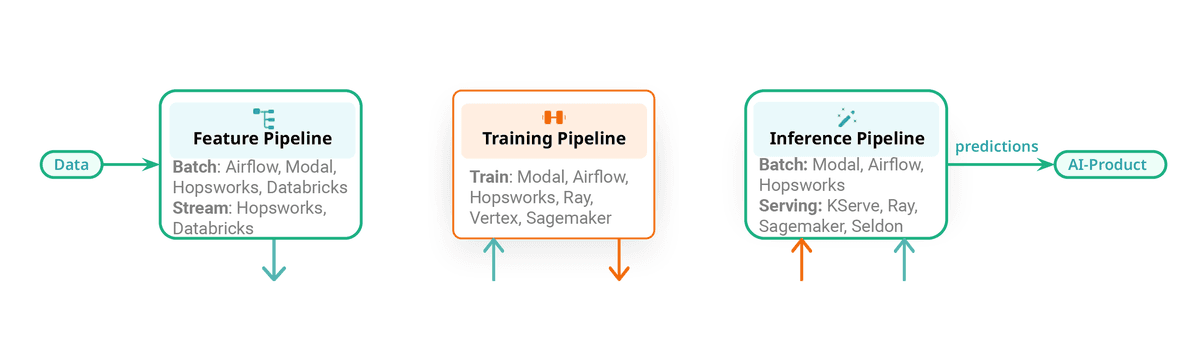
Choose the best orchestrator: Airflow, Modal, Dagster, or Hopsworks built-in. Different teams can use different orchestrators.
CI/CD for ML
Automated testing, versioning, and deployment. GitHub Actions, Airflow, or any orchestrator.
Data Versioning
Reproducible training data with time-travel. Re-create datasets exactly as they were.
Model Serving
KServe-based deployment. Batch, real-time, or streaming inference at scale.
Monitoring
Track feature distributions, model drift, and performance. Real-time alerts.
Governance
Full lineage from raw data to predictions. Audit trails for compliance.
GPU Management
Optimize GPU utilization across training and inference workloads.
Deploy Models at Scale
KServe-based model deployment with automatic scaling. Serve thousands of models in production with real-time predictions and batch inference.
One-click deployment with KServe
Auto-scaling based on traffic
A/B testing and canary deployments
GPU inference for LLMs
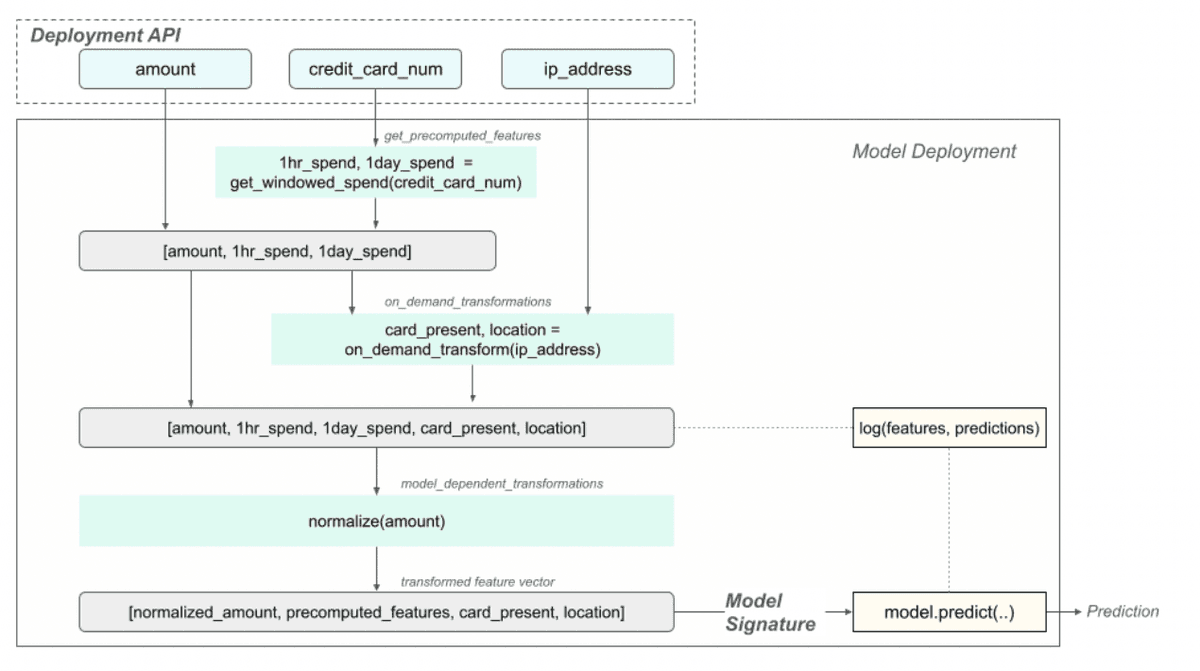
Model deployments build feature vectors, apply transformations, call predict, and log untransformed features for monitoring.
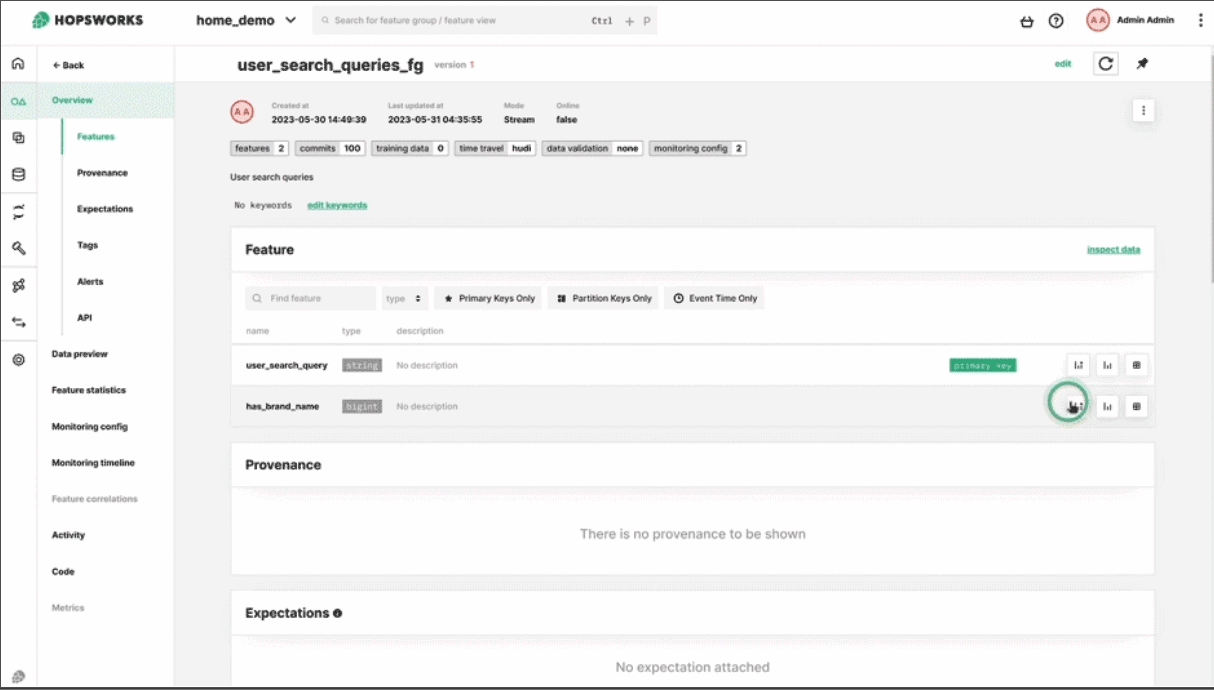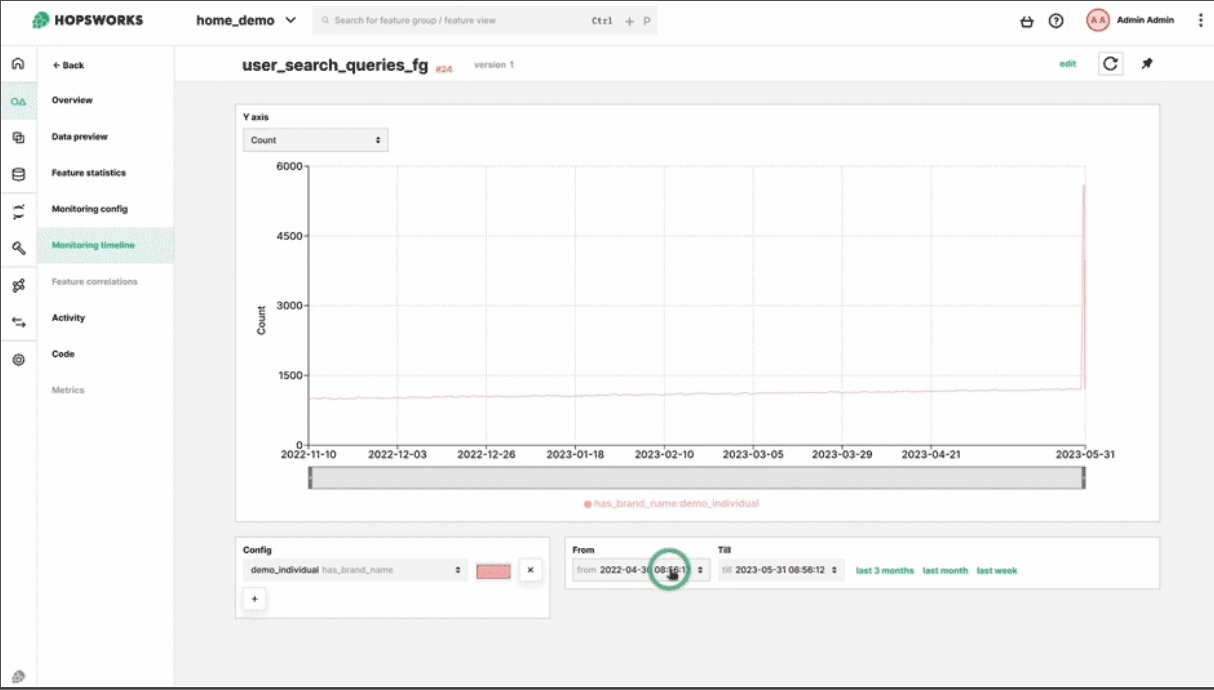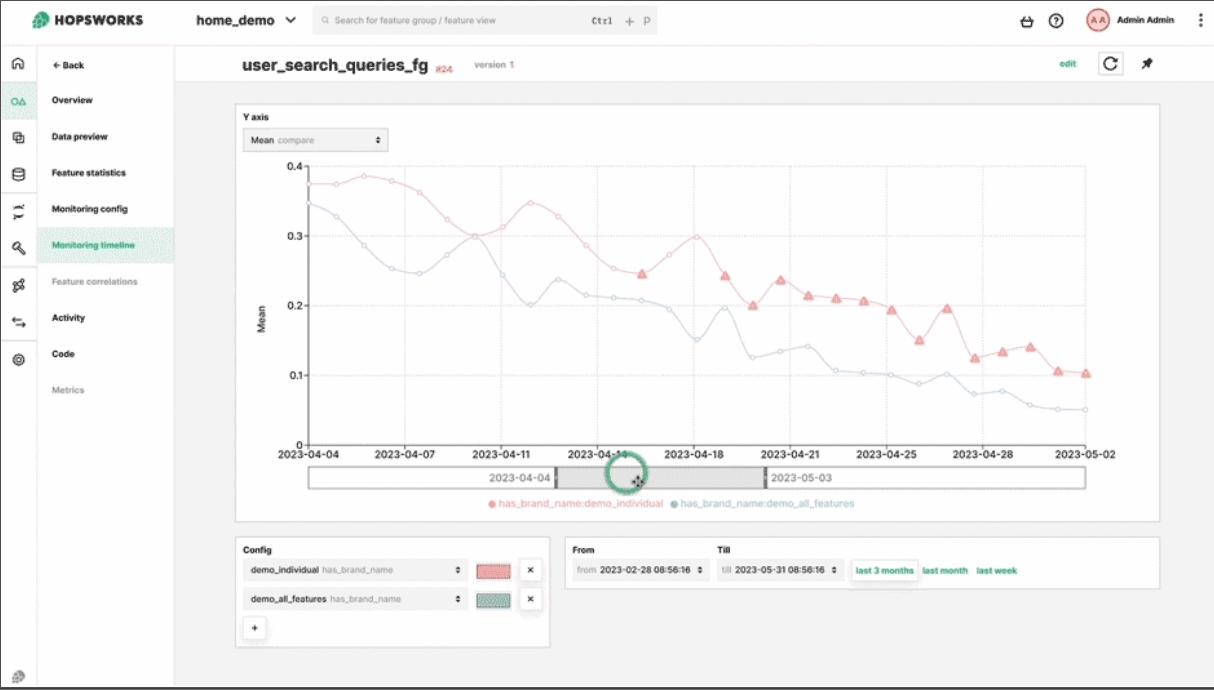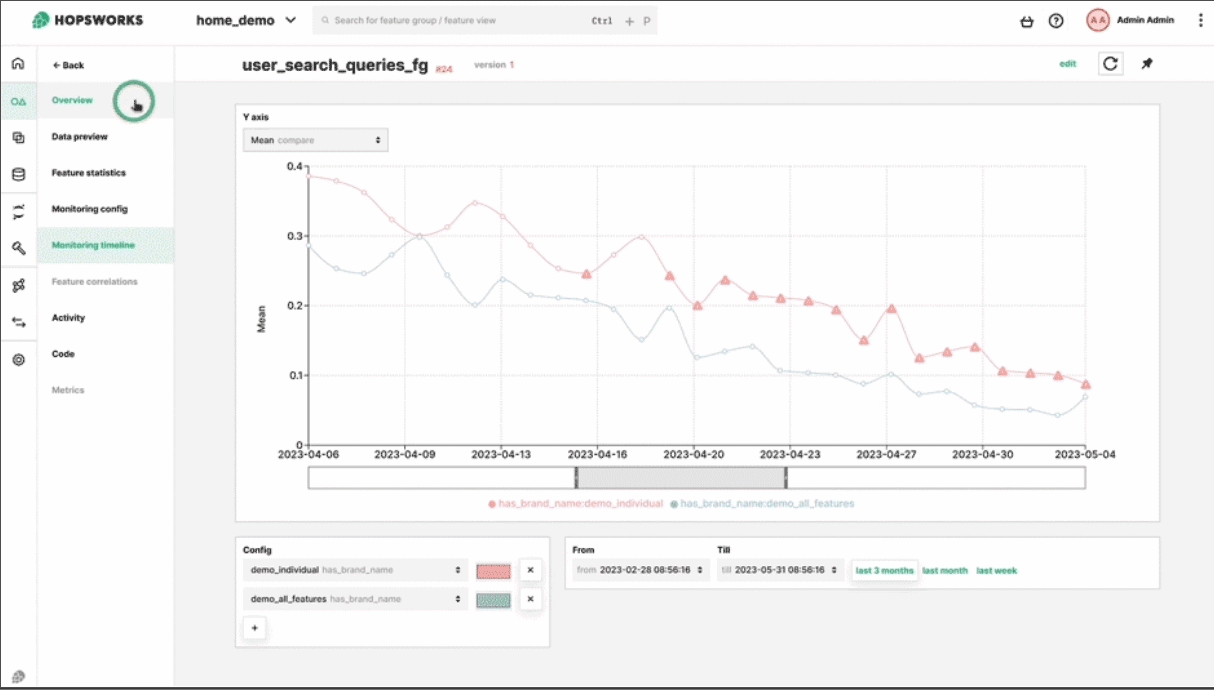
Monitor feature distributions and detect drift in real-time.
Catch Drift Before It Hurts
AI system performance degrades over time due to data drift and model drift. Monitor feature distributions and model predictions to catch issues early.
Feature Monitoring
Track distributions, detect anomalies, receive alerts when data quality degrades.
Model Monitoring
Track prediction distributions, model performance, and bias metrics.
Alerting
Slack, PagerDuty, email - get notified when something goes wrong.
Compliance-Ready AI
AI regulation is coming. The source of bias in many models is their training data. Full lineage from raw data to predictions for audit trails.
Full data lineage and provenance
Reproducible training datasets
Fine-grained access control
Model cards and documentation
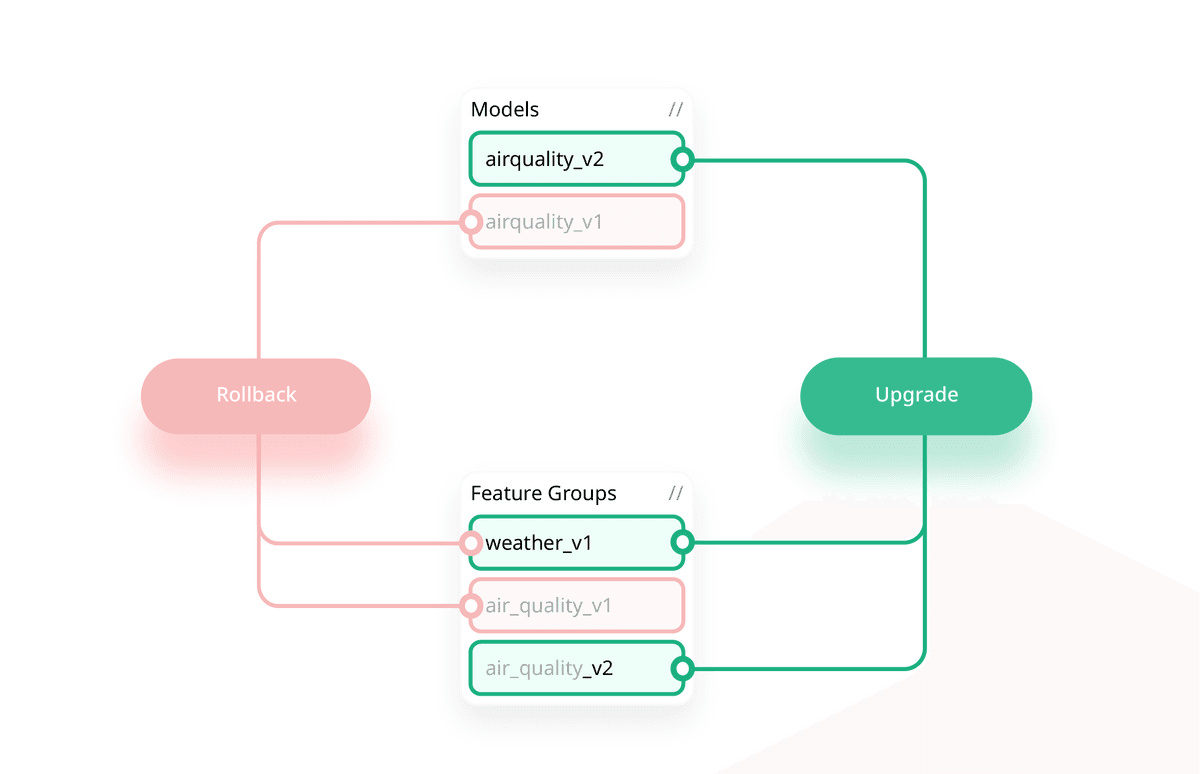
Version models and features together. Push-button upgrade/downgrade in production.
LLMOps is Just MLOps
LLMs follow the same FTI architecture. Feature pipelines for embeddings and RAG, training pipelines for fine-tuning, inference pipelines for agents.
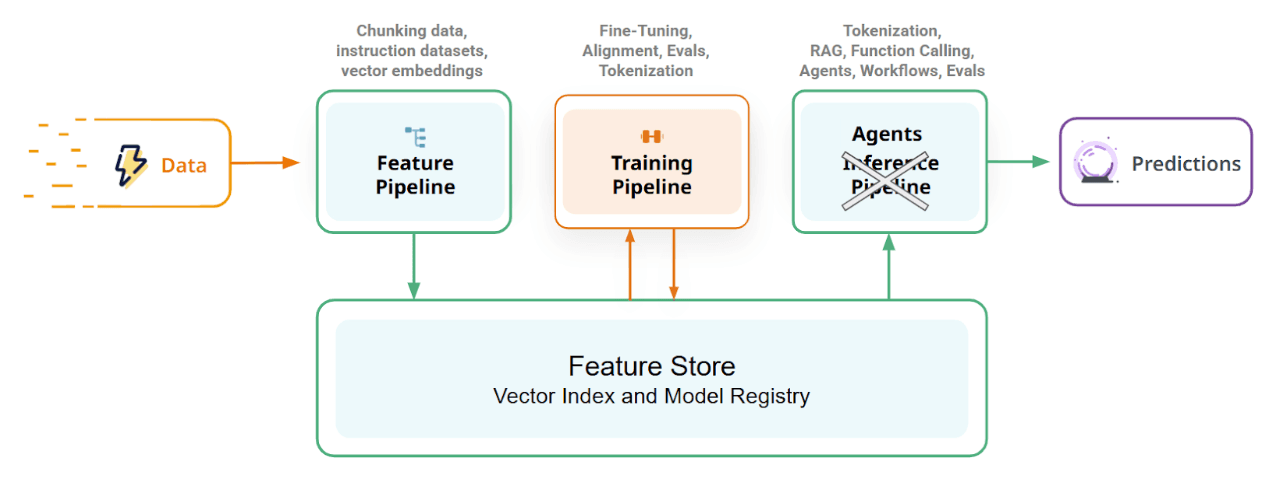
The FTI architecture applied to LLM systems. Online inference pipelines become agents.
Get Models to Production
The FTI architecture has enabled hundreds of developers to build maintainable ML systems. Stop fighting your infrastructure - start shipping AI.