
Scheduled upgrade on April 4, 08:00 UTC
Kindly note that during the maintenance window, app.hopsworks.ai will not be accessible.
April 4, 2025
10
App Status


This article introduces a taxonomy for data transformations in AI applications that is fundamental for any AI system that wants to reuse feature data in more than one model. The taxonomy consists of model-independent data transformations that produce reusable features (for example, total customer spend in the last week), model-dependent transformations that produce features that are specific to one model (for example, normalizing that customer spend value using the mean and standard deviation of all customer spends in the model’s training dataset), and on-demand transformations, found in real-time AI systems, that require data only available at request-time (for example, transforming longitude/latitude to a zipcode). The data transformation taxonomy shows you what data transformations to apply in which AI pipelines, and potential sources of offline-online skew. We finish the article comparing how existing feature stores fare in addressing the taxonomy, and the event-sourcing pattern requires full support for the taxonomy.
This article is part 2 in a 7 part series describing in lay terms concepts and results from a SIGMOD 2024 research paper on the Hopsworks Feature Store.
Other Parts: 1 (Modularity and Composability for AI Systems), 3 (Use all features: Snowflake Schema), 4 (Lakehouse for AI), 5 (From Lakehouse to AI Lakehouse), 6 (Real-Time AI Database), 7 (Reproducible Data).
Many machine learning models require "encoded feature data". That is, a categorical variable transformed into a numerical representation or a numerical variable transformed or scaled to improve model performance. Many data scientists ask an obvious question - should I store encoded feature data in a feature store?
Most existing feature stores do not answer this question in their documentation. ChatGPT confidently gives you the wrong answer. It says you should store encoded feature data in a feature store, hallucinating a number of imagined benefits. One of the few answers you will find on Google is an answer to this Stack Overflow question:
“A consultant from one of the big cloud providers opted for storing encoded features in the store which I find strange because different models will use the same type of feature but will need different encoding procedures and storing encoded value complicates model monitoring and debugging in production.”
I answered that question as I have been teaching about model-independent vs model-dependent transformations since 2022, and given the continued confusion on this topic, I felt compelled to write something more accessible than our research paper linked above.
Data reuse is fundamental to operational, analytical and AI data processing systems. Operational databases organize their data in normalized (2nd/3rd normal form) data models, removing redundant data and reusing tables in views. In data warehousing, the medallion architecture organizes data into bronze, silver, and gold tables, where silver tables reuse bronze tables, gold tables reuse silver tables, and dashboards and AI systems reuse gold tables. Data reuse is less well understood for AI systems, but is still practiced by all hyperscalers. For example, Meta reported that “most features are used by many models”. They specifically said that the most popular 100 features are reused in over 100 different models. They claim feature reuse results in higher quality features through increased usage, reduced storage costs, reduced feature development and operational costs. Like other Enterprises, Meta reuses feature data using a feature store.
Although Meta showed the benefit of feature stores in enabling features to be computed once and then reused in many different models, it is important to note that not all necessary data transformations in an AI system can happen before the feature store. If you store an encoded feature in the feature store, it will prevent a model from reusing that feature if it wants to encode the feature differently. For example, gradient-descent models often work better when numerical features have been normalized, but decision trees do not require normalized numerical features. But, if you do not encode feature data before the feature store, this means that not all data transformations can be performed in your feature pipelines (the data pipelines that transform raw data to features before they are stored in the feature store). Where should you perform the model-specific data transformations for feature encoding? The answer is that they should be performed consistently in training/inference pipelines - without introducing training/inference skew. As we will see later with Hopsworks, a feature store can add support for model-specific data transformations to ensure there is no skew between the training and inference pipelines.
The data transformations familiar to data engineers, such as data cleaning/filtering/aggregations/binning, produce reusable feature data that can be stored in a feature store and used by many models. This feature data is sample-independent - there is no relationship between the feature data and any training datasets created from it.
In contrast, many of the data transformations performed by data scientists transform input data into a numerical format to improve model performance. These model-dependent transformations are typically sample dependent, as they are parameterized by the model’s training dataset. That is, the output of these model-dependent transformations is feature data that is specific to one model - it cannot be reused by other models. Another class of data transformation for AI systems are on-demand transformations that need request-time parameters to be computed. On-demand transformations cannot be precomputed for online inference as they require request-time parameters and functions to compute them can be combined with precomputed data from the feature store.

Data transformations in AI systems are not equivalent, when it comes to feature reuse, as shown in figure 1. Different types of data transformations produce features that can be classified according to a taxonomy.

The data transformation taxonomy for AI is based on the following observations:

A taxonomy is a (often hierarchical) classification, where things are organized into groups or types. From the above observations, we can see that data transformations can be classified as model-independent, model-dependent, or on-demand, see figure 2.
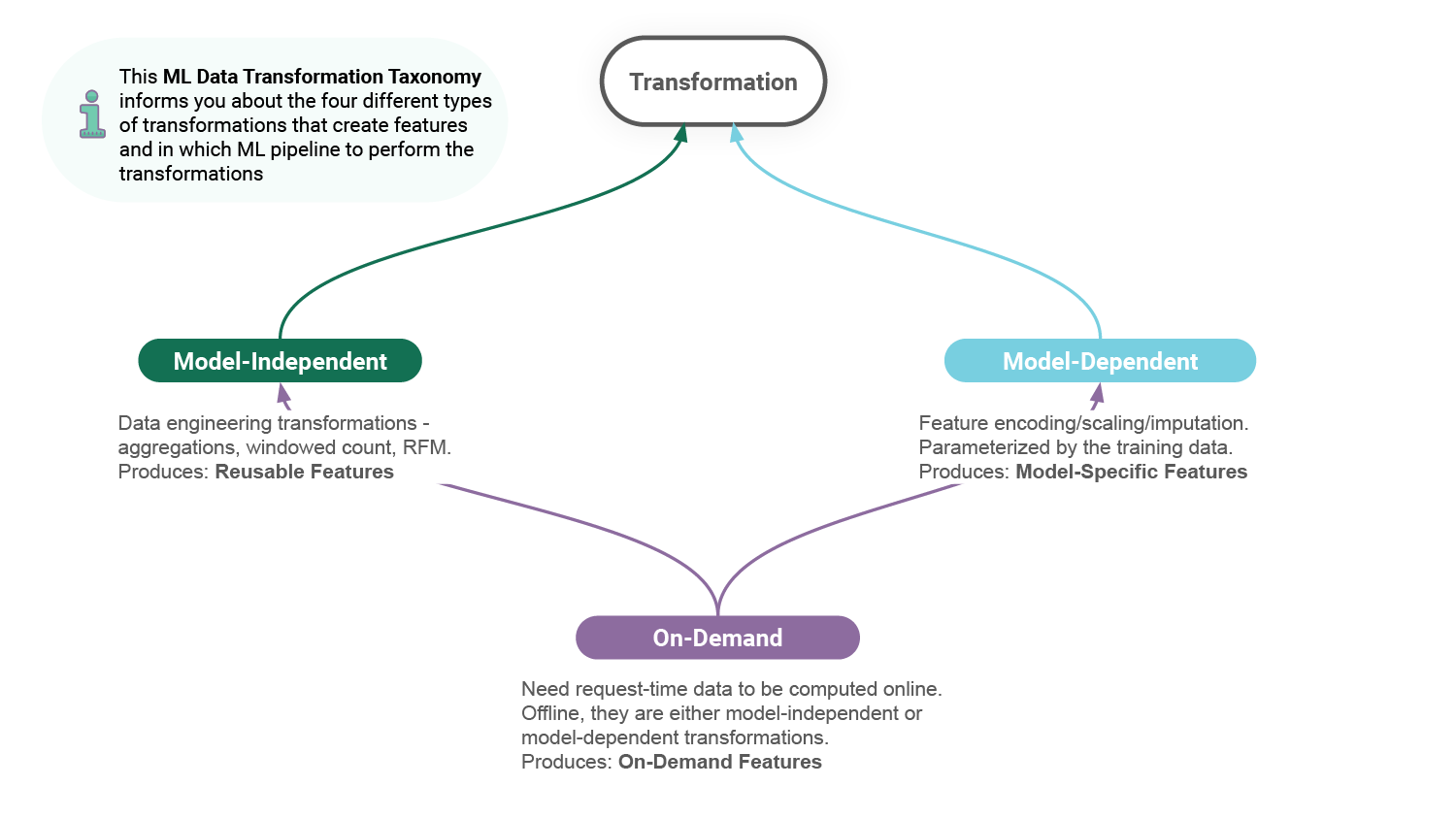
This data transformation taxonomy for AI systems generalizes to any AI system architecture that has separate training and inference programs - which is pretty much all existing AI systems - and reuses features, which is all AI systems that use a feature store.
Figure 3 includes our three different types of data transformations and the AI artifacts created by them. The data that arrives over time in the diagram is typically stored in a feature store, but could be any AI system that manages newly arriving data, where the data is used both for model training and inference.

We note here that model-independent transformations are only found at one place in the diagram, where new and historical data arrives. In contrast, model-dependent transformations and on-demand transformations can be found in two places. Model-dependent transformations need to be applied when creating training data, in training pipelines, but also in inference pipelines, before making predictions. These training and inference pipelines are typically separate programs, which introduces the possibility of skew between the implementations (see online-offline skew). Similarly, on-demand transformations are found in online inference pipelines, but may also be applied to backfill feature data from historical data in a feature pipeline. Again, online inference programs and feature pipelines are typically separate programs, meaning there is potential for skew between the two on-demand transformations (for example, if there are two different implementations of the on-demand transformation). Online-offline skew is a general challenge for AI systems, and the data transformation taxonomy helps provide an understanding of its cause and alerts you where it can occur, so you can prevent it occurring. In general, the taxonomy also applies to any AI system that aims to create reusable feature data, where solutions to online-offline skew will always need to be provided.
Model-dependent transformations produce feature data that is specific to one model. When data scientists talk about transformations, they typically refer to model-dependent transformations, such as transforming a categorical variable into a numerical format or scaling/normalizing/standardizing a numerical variable to improve the performance of your gradient-based ML model. Feature encoding is the most common example of model-dependent transformations in AI systems. Feature encoding transformations are parameterized by the model’s training dataset (they are sample dependent), and as most models typically have their own training dataset, the output data from feature encoding is specific to only that one model. Similarly, transformations that impute missing data are typically parameterized by the training dataset, and are, therefore, model-dependent transformations.
A well known example of a model-dependent transformation for LLMs, is text tokenization. Each LLM typically has their own tokenizer, and, therefore, tokenization is a model-dependent transformation. For example, if you were to tokenize text when creating instruction datasets for LLM fine-tuning, the tokenized text would not be reusable for fine-tuning a different LLM. This means you should not tokenize text in feature pipelines, where model-independent transformations are performed. Instead, your feature pipeline should create clear-text instruction datasets for fine-tuning, and tokenization should be performed in both the training and inference pipelines, where model-dependent transformations are performed, see figure 4.

Model-independent transformations produce features that can be reused in many models. They cover the types of transformations that data engineers are very familiar with that are widely used in feature engineering, such as:
Model-independent transformations are applied once in batch or streaming feature pipelines, see figure 5.

The reusable feature data output by feature pipelines is stored in a feature store, to be later used by downstream training and inference pipelines.
On-demand transformations are found in real-time AI systems, see figure 6. In an online inference pipeline, an on-demand transformation requires input data that is only available at prediction request time. If an on-demand transformation is implemented as a function, that function has at least one parameter that originates from the prediction request. The function may also include (precomputed feature) parameters that originate from a feature store.

When historical data used to compute on-demand features is available, you can use the on-demand feature function to backfill feature data to a feature store. For example, in figure 7, you can see an event-sourcing pattern, where event data in Kafka is stored in a S3 data lake. You can use that historical data to create on-demand features by applying the same on-demand transformation function on the event data in a feature pipeline.

The features created can then be used as training data for models. The feature data created should be model-independent as the transformation should not have model-specific output. If the transformation is model-specific, it should be performed in a model-dependent transformation that can be performed consistently after reading the feature data from the feature store (for historical data) and after any on-demand transformations functions in an online inference pipeline. Note that the model-independent requirement for on-demand transformations means just that the transformation should create sample-independent feature data - it is not parameterized by the training dataset or model itself. An on-demand feature may ultimately only be used by one model, but if its transformations are model-independent, it does not need to be performed in a model-dependent transformation. The benefit of computing on-demand feature data in a feature pipeline over model-dependent transformations in a training pipeline is that you only need to compute them once, not every time you create a training dataset.
So, you should factor out those parts of the online transformation that are model-specific (such as feature encoding) from those that are model-independent. The parts that are model-independent go in the on-demand transformation logic, while model-specific transformations still happen in model-dependent transformations. In online inference, the output of an on-demand transformation function is passed through model-dependent transformations before it is received by the model.

In Figure 8, you can see an architecture diagram from an unnamed payments company that did not include a feature store to store the output of their on-demand transformation functions on historical data. The result is massively decreased productivity for data scientists, as any changes to training datasets require many hours of massive PySpark jobs to recompute the training data. A feature store that supports model-independent on-demand transformation functions (like Hopsworks) would have enabled them to compute the feature data incrementally as new events arrive, and create new training datasets in seconds (for EDA) or minutes (for full training). Feature stores that treat on-demand transformation functions as model-dependent transformations (Databricks, Tecton) have the same problem as the payments company below - they have to recompute all on-demand features every time they want to create new training data with them.

On-demand transformations are typically implemented as functions in online inference pipelines. A previous generation of feature stores implemented on-demand transformations as microservices (or serverless functions) that are invoked from online inference pipelines. The problem with this approach, however, is that for every new on-demand feature you add to your online model, you get large increases in latency due to straggler effects and the tail-at-scale from network calls. They are also massively inefficient in batch pipelines for backfilling with historical data. On-demand features as functions, in contrast, use the same programming language as the model was trained in (typically Python). In Python-based feature pipelines and online inference pipelines, you can implement the on-demand transformations as Python UDFs (although they do not scale for backfilling) or Pandas UDFs (that scale for backfilling, but add some latency to online inference).
The data transformation taxonomy for AI systems is most relevant for feature stores that all support the computation of features once, and their subsequent reuse in many models. Table 2 summarizes the current support of well-known feature stores for the taxonomy.

Firstly, Hopsworks is the only feature store to support the full taxonomy, with open APIs for feature engineering, enabling support for a wide range of compute engines for model-independent transformations. Model-dependent transformations and on-demand transformations are supported as Pandas or Python user-defined functions (UDFs).
In Databricks, model-independent transformations are supported in PySpark and SQL, while Tecton provides a domain-specific language (DSL) for defining model-independent transformations that are transpiled into Spark, SQL, or Rift (their DuckDB engine) for execution. Both Databricks and Tecton support computing features using request-time parameters with Python UDFs. Tecton also supports Pandas UDFs.. These on-demand transformations are model-dependent transformations applied to request-time (and historical) parameters. Neither feature store supports model-independent on-demand transformations in feature pipelines to precompute feature data for the feature store. Model-dependent transformations are not explicitly supported, except as on-demand transformations. Neither of these feature stores has support for declarative model-dependent transformations for encoding a categorical/numerical feature (found in Hopsworks).
The other feature stores - AWS Sagemaker, GCP Vertex, and Snowflake - only support model-independent transformations, mostly with SQL and some Python support. This makes it challenging to build real-time AI systems that require on-demand transformations.
It is possible to implement your own model-dependent transformations by tightly coupling them with your model, for example, using Scikit-Learn pipelines (as shown here in Hopsworks lending club tutorial). A Scikit-Learn pipeline can be designed to contain a series of model-dependent transformation steps before either model.fit() or model.predict() is invoked as part of the pipeline. If you save and package your Scikit-Learn pipeline along with your versioned model in your model registry (see example training pipeline), then in your inference pipeline when you download the versioned model, you get exactly the same pipeline object (and model-dependent transformations). Similarly, TensorFlow enables you to perform a limited number of model-dependent transformations in pre-processing layers for the model. In PyTorch, the transforms API is often used for model-dependent transformations.
One disadvantage of preprocessing pipelines is that they consume CPU cycles and may cause under utilization of GPUs in model training or inference. If your model-dependent transformations are too CPU-intensive, it may not be possible to run your GPUs at maximum capacity. An alternative is to introduce a training dataset creation pipeline that creates training data as files, after applying model-dependent transformation functions. This is possible in Hopsworks with feature views.
In Hopsworks, an AI system is typically decomposed into different AI pipelines that fall into one of the following categories:
Each of these AI pipelines has a different role in transforming data so that it gets progressively closer to the input data used for model training and inference. Another sub-pipeline of the training pipeline is the training dataset pipeline that reads features (and labels) from the feature store, applies model-dependent transformations and outputs training data as files. Training dataset pipelines are important when training data is large, and needs to be streamed into workers, and when model-dependent transformations are expensive and can be applied before the model training pipeline.
Hopsworks stores feature data in feature groups (tables containing feature data in an offline store and an online store). Feature data is read for both training and inference, however, using a feature view, not using feature groups directly. A feature view is a meta-data only selection of features (from potentially different feature groups) that include the input and output schema for a model. That is, the feature view describes the input features, the output target(s) as well as any helper columns used for training or inference. But a feature view is not only a schema, it can also include model-dependent transformations. Transformations are included in feature views as their primary goal is to prevent skew between training and inference pipelines - whether that is the model schema or model-dependent transformations.
Feature views are used to create consistent snapshots of data for both training and inference. The feature view also computes and saves statistics for the training datasets it creates, and these statistics are made available as parameters for many model-dependent transformations (like categorical encoding, normalization, scaling) in both training and inference, see Figure 9.

In Figure 9, we can also see that on-demand transformations may need to be kept consistent between online inference pipelines and feature pipelines. We use on-demand transformations in feature pipelines to backfill feature data for training using historical data. In Hopsworks, you can register those on-demand features with feature groups and, through lineage, use exactly the same on-demand transformation in online inference.
You can define model-dependent transformations and on-demand transformations in Hopsworks as either Pandas or Python user-defined functions (UDFs). Pandas UDFs enable the vectorized execution of the transformation functions, providing orders of magnitude higher throughput compared to Python UDFs. Pandas UDFs can also be scaled out in workers in a Spark program, enabling scaling from GBs to TBs or more. Here is an example of declarative model-dependent transformation function - one-hot encoding is applied to the city feature in the my_fv feature view:
For on-demand features, you implement the same Pandas/Python UDF, one for each on-demand feature:
If you intend to reuse feature data in many models, you need to first understand the data transformation taxonomy, so that you know what data transformations to put in your different AI pipelines. Feature stores can help by providing infrastructure support for the data transformation taxonomy, but currently only Hopsworks Feature Store supports the complete taxonomy.



.svg)


.png)