Manage your own Feature Store on Kubeflow with Hopsworks
Learn how to integrate Kubeflow with Hopsworks and take advantage of its Feature Store and scale-out deep learning capabilities.

Feature stores are key components in enterprises’ machine learning/artificial intelligence architectures. In previous blog posts, we introduced the feature store, MLOps with a feature store, and how to use the Hopsworks Feature Store in Databricks and AWS Sagemaker. In this blog post, we focus on how to integrate Kubeflow with the Hopsworks Feature Store. Hopsworks is available as an open-source platform, but integrations with external platforms, like Kubeflow, are only available on either our SaaS or Enterprise versions.
Hopsworks is a modular platform that includes a feature store, a compute engine ((Py)Spark, Python, Flink), a data science studio, a file system (HopsFS/S3), and model serving/monitoring support. The Hopsworks Feature Store can be used as a standalone feature store by Kubeflow. As Kubernetes has limited support for Spark (Spark-on-k8s still has problems with shuffle, as of June 2020), Hopsworks is often used for both its feature store and Spark and scale-out deep learning capabilities.
Hopsworks offers a centralized platform to manage, govern, discover, and use features. Features can be used:
- at scale to create train/test datasets,
- for model scoring in analytical (batch application) models,
- at low latency by operational models to enrich feature vectors.
Get Started
Before you begin, make sure you have started a Hopsworks cluster. If you are on AWS, we recommend using our managed platform Hopsworks. If you are on GCP, Azure or on-premises, as of June 2020, you have to use the hopsworks-installer script to install Hopsworks.
Hopsworks should be installed so that Kubeflow has access to the private IPs of the feature store services: Hive Server 2 and the Hopsworks REST API endpoint. On GCP, this means you should install your Hopsworks cluster in the same Region/Zone as your Kubeflow cluster. Similarly, on AWS, your Hopsworks cluster should be installed in the same VPC/subnet as Kubeflow. And on Azure, your Hopsworks cluster should be installed in the same resource group as your Kubeflow cluster.
API Key
From a Jupyter notebook in Kubeflow, you need to be able to authenticate and interact with the Hopsworks Feature Store. As such you need to get an API key from Hopsworks. You can generate an API key by clicking on your username in the top right of the window, click on Settings and select API KEY.
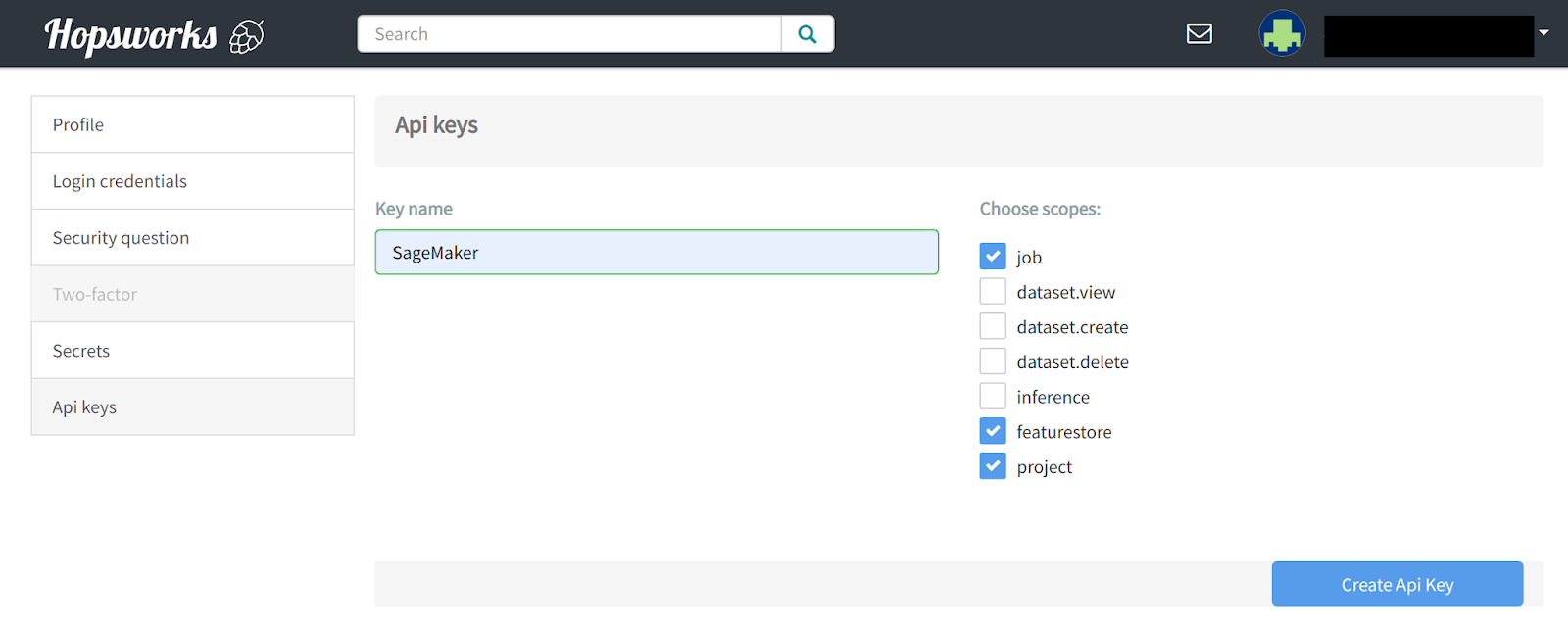
You need to choose the featurestore, jobs, and project scopes when creating your API key. You should save your API key to a file, with the path API_KEY_FILE, that will be accessible from your Jupyter notebook in Kubeflow.
Hopsworks-cloud-sdk
With the API key configured correctly, in your KubeFlow Jupyter notebook, you should be able to install the hopsworks-cloud-sdk library using PIP:
Make sure that the hopsworks-cloud-sdk library version matches the installed version of Hopsworks.
Establish the first connection
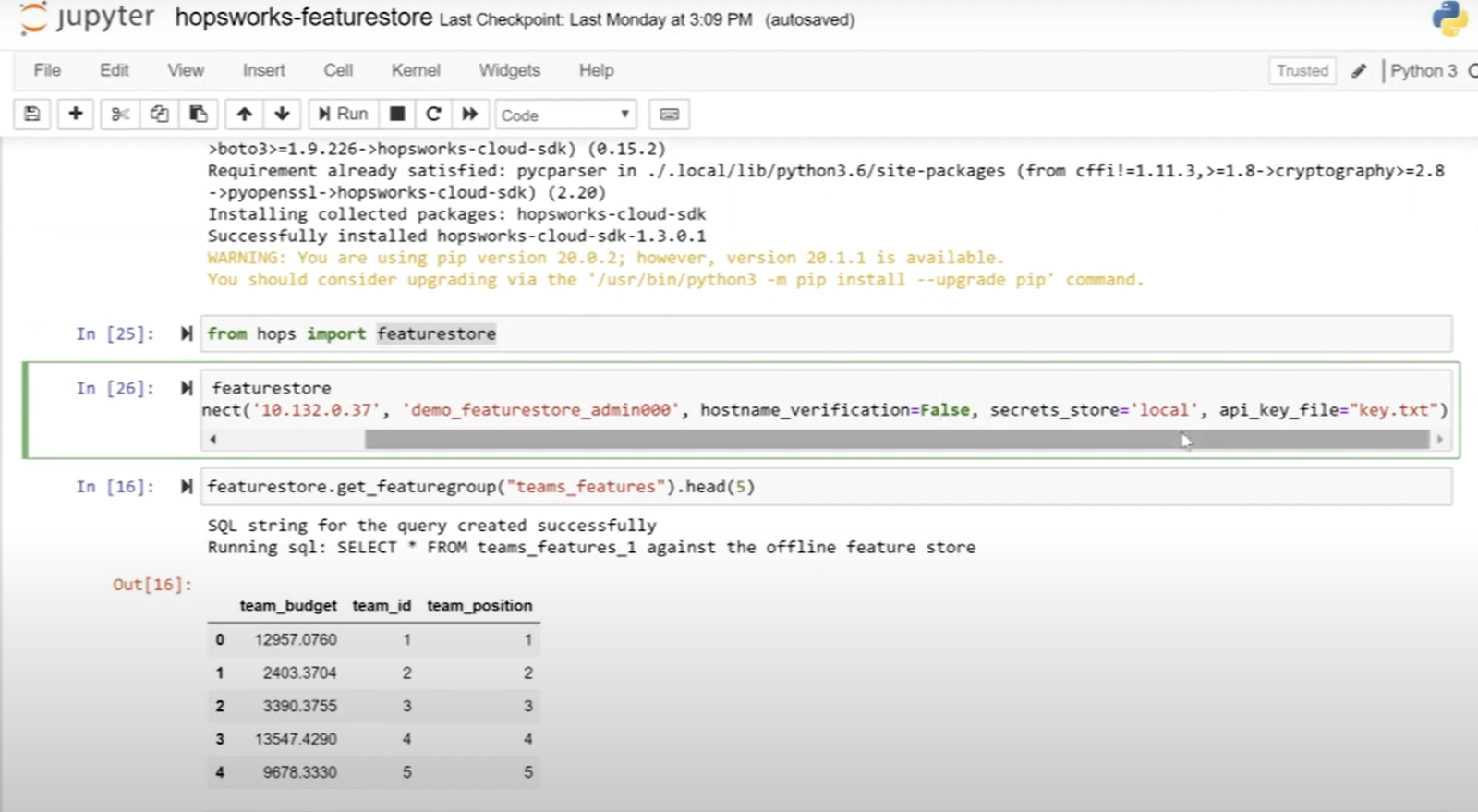
From your Jupyter notebook, the API Key should now be readable from the local file system at the path API_KEY_FILE, and the hopsworks-cloud-sdk library should be installed. You should be now able to establish a connection to the feature store, and start using the Hopsworks - Kubeflow integration with this connect call:
Upcoming improvements
Several exciting improvements are coming to the Hopsworks feature store APIs in the next couple of weeks. The most important one is a more expressive API for joining features together. The new API is heavily inspired by Pandas dataframe joining and should make life easier for data scientists. Moreover, we are adding the capability to register a small Pandas dataframe as a feature group directly from a python-kernel in a Jupyter notebook. It will also be possible to ingest Pandas dataframes as feature groups without the need for PySpark.