ExtremeEarth scales AI to the Earth Observation Community with Hopsworks
Read how ExtremeEarth brings Large-scale AI to the Earth Observation Community with Hopsworks, the Data-intensive AI Platform.

This article was originally published at Extreme Earth.
In recent years, unprecedented volumes of data are generated in various domains. Copernicus, a European Union flagship programme, produces more than three petabytes(PB) of Earth Observation (EO) data annually from Sentinel satellites [1]. This data is made readily available to researchers that are using it, among other things, to develop Artificial Intelligence (AI) algorithms in particular using Deep Learning (DL) techniques that are suitable for Big Data. One of the greatest challenges that researchers face however, is the lack of tools that can help them unlock the potential of this data deluge and develop predictive and classification AI models.
ExtremeEarth is an EU-funded project that aims to develop use-cases that demonstrate how researchers can apply Deep Learning in order to make use of Copernicus data in the various EU Thematic Exploitation Platforms (TEPs). A main differentiator of ExtremeEarth to other such projects is the use of Hopsworks, a Data-Intensive AI software platform for scalable Deep Learning. Hopsworks is being extended as part of ExtremeEarth to bring specialized AI tools for EO data and the EO data community in general.
Hopsworks, Earth Observation Data and AI in one Platform
Hopsworks is a Data-Intensive AI platform which brings a collaborative data science environment to researchers who need a horizontally scalable solution to developing AI models using Deep Learning. Collaborative means that users of the platform get access to different workspaces, called projects, where they can share data and programs with their colleagues, hence improving collaboration and increasing productivity. The Python programming language has become the lingua franca amongst data scientists and Hopsworks is a Python-first platform, as it provides all the tools needed to get started programming with Python and Big Data. Hopsworks integrates with Apache Spark and PySpark, a popular distributed processing framework.
Hopsworks brings to the Copernicus program and the EO data community essential features required for developing aI applications at scale, such as distributed Deep Learning with Graphics Processing Units (GPUs) on multiple servers, as demanded by the Copernicus volumes of data. Hopsworks provides services that facilitate conducting Deep Learning experiments, all the way from doing feature engineering with the Feature Store [2], to developing Deep Learning models with the Experiments and Models services that allow them to manage and monitor Deep Learning artifacts such as experiments, models and automated code-versioning and much more [3]. Hopsworks storage and metadata layer is built on top of HopsFS, the award-winning highly scalable distributed file system [4], which enables Hopsworks to meet the extreme storage and computational demands of the ExtremeEarth project.
Hopsworks brings horizontally scalable Deep Learning for EO data close to where the data lives, as it can be deployed on Data and Information Access Services (DIAS) [5]. The latter provides centralised access to Copernicus data and information which combined with the AI for EO data capabilities that Hopsworks brings, an unparalleled data science environment is made available to researchers and data scientists of the EO data community.
Challenges of Deep Learning with EO Data
Recent years have witnessed the performance leaps of Deep Learning (DL) models thanks to the availability of big datasets (e.g. ImageNet) and the improvement of computation capabilities (e.g., GPUs and cloud environments). Hence, with the massive amount of data coming from earth observation satellites such as the Sentinel constellation, DL models can be used for a variety of EO-related tasks. Examples of these tasks are sea-ice classification, monitoring of water flows, and calculating vegetation indices.
However, together with the performance gains comes many challenges for applying DL to EO tasks, including, but not limited to:
Labeled datasets for training;
While collecting raw Synthetic-Aperture Radar (SAR) images from the satellites is one thing, labeling those images to make them suitable for supervised DL is yet a time consuming task. Should we seek help from unsupervised or semi-supervised learning approaches to eliminate the need for labeled datasets? Or should we start building tools to make annotating the datasets easier?
Interpretable and Human-understandable models or EO tasks;
Given enough labeled data, we can probably build a model with satisfactory performance. But how can we justify the reasons behind why the model makes certain predictions given certain inputs? While we can extract the intermediate predictions for given outputs, can we reach interpretations that can be better understood by humans?
Management of very large datasets;
Managing terabytes (TB) of data that can still fit into a single machine is one thing, but managing petabytes (PB) of data that requires distributed storage and provides a good service for the DL algorithms so as not to slow down the training and serving process is a totally different challenge. To further complicate the management, what about partial failures in the distributed file system? How shall we handle them?
Heterogeneous data sources and modalities (e.g., SAR images from satellites, sensor readings from ground weather stations);
How can we build models that effectively use multi-modalities? For example, how can we utilize the geo-location information in an image classification model?
DL architectures and learning algorithms for spectral, spatial, and temporal data;
While we might be able to perform preprocessing and design model architectures for RGB image classification, how do these apply to SAR images? Can we use the same model architectures? How to extract useful information from multi-spectral images?
Training and fine-tuning (hyperparameter optimizations) of DL models;
Hyperparameters are those parameters of the training process (e.g., the learning rate of the optimizer, or the size of the convolution windows) that should be manually set before training. How can we effectively train models and tune the hyperparameters? Should we change the code manually? Or can we use frameworks to provide some kind of automation?
The real time requirements for serving DL models;
Once the training is done, we want to use our trained model to predict outcomes based on the newly observed data. Often these predictions have to be made in real-time or near-real-time to make quick decisions. For example, we want to update the ice charts of the shipping routes every hour. How to serve our DL models online to meet these real-time requirements?
Deep Learning Pipelines for EO Data with Hopsworks
A Data Science application in the domain of Big Data typically consists of a set of stages that form a Deep Learning pipeline. ُThis pipeline is responsible for managing the lifecycle of data that comes into the platform and is to be used for developing machine learning models. In the EO data domain in particular, these pipelines need to scale to the petabyte-scale data that is available within the Copernicus program. Hopsworks provides data scientists with all the required tools to build and orchestrate each stage of the pipeline, depicted in the following diagram.
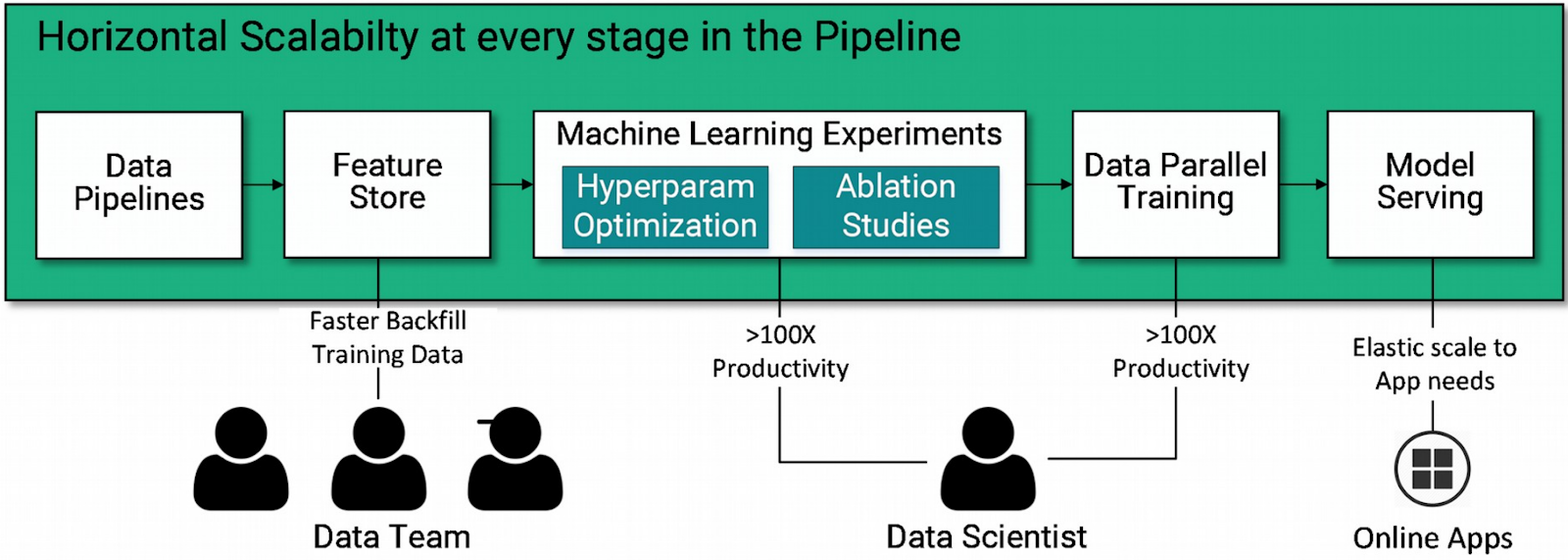
In detail, a typical Deep Learning pipeline would consist of:
- Data Ingestion: The first step is to collect and insert data into the AI platform where the pipeline is to be run. A great variety of data sources can be used such as Internet of Things (IoT) devices, web-service APIs etc. In ExtremeEarth, the data typically resides on the DIAS which can be directly accessed from Hopsworks.
- Data Validation: Tools such as Apache Spark that can cope with Big Data are typically employed to validate incoming data that is to be used in later stages. For example data might need to be parsed and cleaned up from duplicate or missing values or a simple transformation of an alphanumeric field to a numeric one might be needed.
- Feature Engineering: Before making use of the validated data to develop DL models, the features that will be used to develop such models need to be defined, computed and persisted. Hopsworks Feature Store is the service that data engineers and data scientists use for such tasks, as it provides rich APIs, scalability and elasticity to cope with varying data volumes and complex data types and relations. For example users can create groups of features or compute new features such as aggregations of existing ones.
- Model development (Training): Data scientists can greatly benefit from a rich experiment API provided by Hopsworks to run their machine learning code, whether it be TensorFlow, Keras, PyTorch or another framework with a Python API. In addition, Hopsworks manages GPU allocation across the entire cluster and facilitates distributed training which involves making use of multiple machines with multiple GPUs per machine in order to train bigger models and faster [9]
- Model Serving & Monitoring: Typically the output of the previous stage is a DL model. To make use of it, users can submit inference requests by using the Hopsworks built-in elastic model serving infrastructure for TensorFlow and scikit-learn, two popular machine learning frameworks. Models can also be exported in the previous pipeline and downloaded from Hopsworks directly to be embedded into external applications, such as iceberg detection and water availability detection in food crops. Hopsworks also provides infrastructure for model monitoring, that is continuously monitoring the requests being submitted to the model and its responses and users can then apply their own business logic on which actions to take depending on how the monitoring metrics output changes over time.
Example Use Case: Iceberg Classification with Hopsworks
Drifting icebergs pose major threats to the safety of navigation in areas where icebergs might appear, e.g., the Northern Sea Route and North-West Passage. Currently, domain experts manually conduct what is known as an “ice chart” on a daily basis, and send it to ships and vessels. This is a time-consuming and repetitive task, and automating it using DL models for iceberg classification would result in generation of more accurate and more frequent ice charts, which in turn leads to safer navigation in concerned routes.
Iceberg classification is concerned with telling whether a given SAR image patch contains an iceberg or not. Details of the classification depends on the dataset that will be used. For example, given the Statoil/C-CORE Iceberg Classifier Challenge dataset [6], the main task is to train a DL model that can predict whether an image contains a ship or an iceberg (binary classification).

Satellite radar images from the Statoil/C-CORE Iceberg Classifier Challenge [6]
The steps we took to develop and serve the model were the following:
- First step is preprocessing. We read the data which is stored in JSON format and create a new feature which is the average of the satellite image bands.
- Second step is inserting the data into the Feature Store which provides APIs for managing feature groups and creating training and test datasets. In this case, we created the training and test datasets in TFRecord format after scaling the images as we are using TensorFlow for training.
- Third step is building and training our DL model on Hopsworks. Since the dataset is not very complicated and we have a binary classification task, using a DL model that is very similar to LeNet-5 [7] yields 87% accuracy on the validation set after 20 epochs of training which takes 60 seconds to train on a Nvidia GTX1080. This step also includes hyperparameter tuning. Ablation studies, in which we remove different components (e.g., different convolutional layers, or dataset features) can also be employed to gain more insights about the model. Hopsworks provides efficient and easy support for hyperparameter tuning and ablation studies through a Python-based framework called Maggy [8]. Finally, to further increase the training speed, the distributed training strategy provided in Hopworks can be used.
The final step is to export and serve the model. Model is exported and saved into the Hopsworks “Models” dataset. Then we use the Hopsworks elastic model serving infrastructure to host TensorFlow serving which can scale with the number of inference requests.
Conclusion
In this blog post we described how the ExtremeEarth project brings new tools and capabilities with Hopsworks to the EO data community and the Copernicus program. We also showed how we have developed a practical use case by using Copernicus data and Hopsworks. We keep developing Hopsworks to make it even more akin to the tools and processes used by researchers across the entire EO community and we continue development of our use cases with more sophisticated models using even more advanced distributed Deep Learning training techniques.