HopsFS file system: 100X Times Faster than AWS S3
Many developers believe S3 is the "end of file system history". It is impossible to build a file/object storage system on AWS that can compete with S3 on cost. But what if you could build on top of S3

The Dumb Bucket
S3 has become the de-facto platform for storage in AWS due to its scalability, high availability, and low cost. However, S3 provides weaker guarantees and lower performance compared to distributed hierarchical file systems. Despite this, many developers erroneously believe that S3 is the end of file system history - there is no alternative to S3, so just re-write applications to account for its limitations (such as slow and inconsistent file listings, non atomic file/dir rename, closed metadata, and limited change data capture (CDC) support).
Azure has built an improved file system, Azure Data Lake Storage (ADLS) V2, on top of Azure Blob Storage (ABS) service. ADLS provides a HDFS API to access data stored in a ABS container, giving improved performance and POSIX-like goodness. But, until today, there has been no equivalent to ADLS for S3. Today, we are launching HopsFS as part of Hopsworks.
Hierarchical Distributed File Systems strike back in the Cloud
Hierarchical distributed file systems (like HDFS, CephFS, GlusterFS) were not scalable enough or highly available across availability zones in the cloud, motivating the move to S3 as the scalable storage service of choice. In addition to the technical challenges, AWS have priced virtual machine storage and inter-availability zone network traffic so high that no third party vendor could build a storage system that offers a per-byte storage cost close in price to S3.
However, the move to S3 has not been without costs. Many applications need to be rewritten as the stronger POSIX-like behaviour of hierarchical file systems (atomic move/rename, consistent file listings, consistent read-after-writes) has been replaced by weakened guarantees in S3.
Even simple tasks, such as finding out what files you have, cannot be easily done on S3 when you have enough files, so a new service was introduced to enable you to pay extra to get a stale listing of your files. Most analytical applications (e.g., on EMR) use EMRFS, instead of S3, which is a new metadata layer for S3 that provides slightly stronger guarantees than S3 - such as consistent file listings.
File systems are making the same Journey as Databases
The journey from a stronger POSIX-like file system to a weaker object storage paradigm and back again has parallels in the journey that databases have made in recent years. Databases made the transition from strongly consistent single-host systems (relational databases) to highly available (HA), eventually consistent distributed systems (NoSQL systems) to handle the massive increases in data managed by databases. However, NoSQL is just too hard for developers, and databases are returning to strongly consistent (but now scalable) NewSQL systems, with databases such as Spanner, CockroachDB, SingleSQL, and MySQL Cluster.
In this blog, we show that distributed hierarchical file systems are completing a similar journey, going from strongly consistent POSIX-compliant file systems to object stores (with their weaker consistency models, but high availability across data centers), and back to distributed hierarchical file systems that are HA across data centers, without any loss in performance and, crucially, without any increase in cost, as we will use S3 as block storage for our file system.
HopsFS
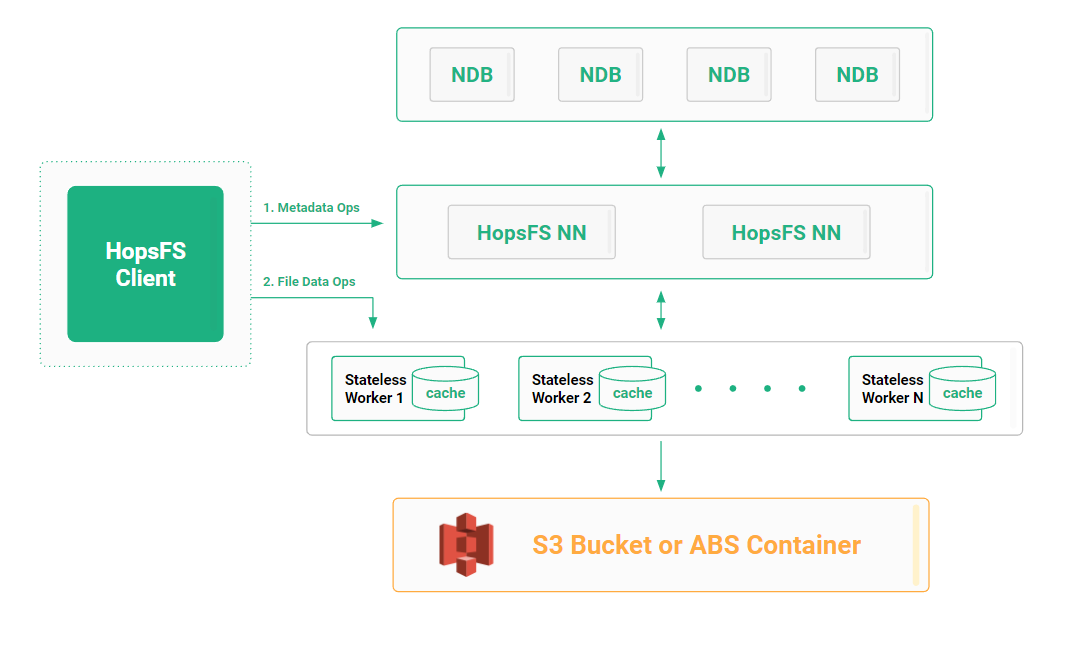
HopsFS is a hierarchical distributed file system that provides a HDFS API (POSIX-like API), but stores its data in a bucket in S3. We redesigned HopsFS to (1) be highly available across availability zones in the cloud and (2) to transparently use S3 to store the file’s blocks without sacrificing the file system’s semantics. The original data nodes in HopsFS have now become stateless workers (part of a standard Hopsworks cluster) that include a new block caching service to leverage faster local VM storage for hot blocks.
It is important to note that the cache is a global cache - not a local worker cache found in other vendor’s Spark workers - that includes secure access control to the cache. In our experiments, we show that HopsFS outperforms EMRFS (S3 with metadata in DynamoDB for improved performance) for IO-bound workloads, with up to 20% higher performance and delivers up to 3.4X the aggregated read throughput of EMRFS.
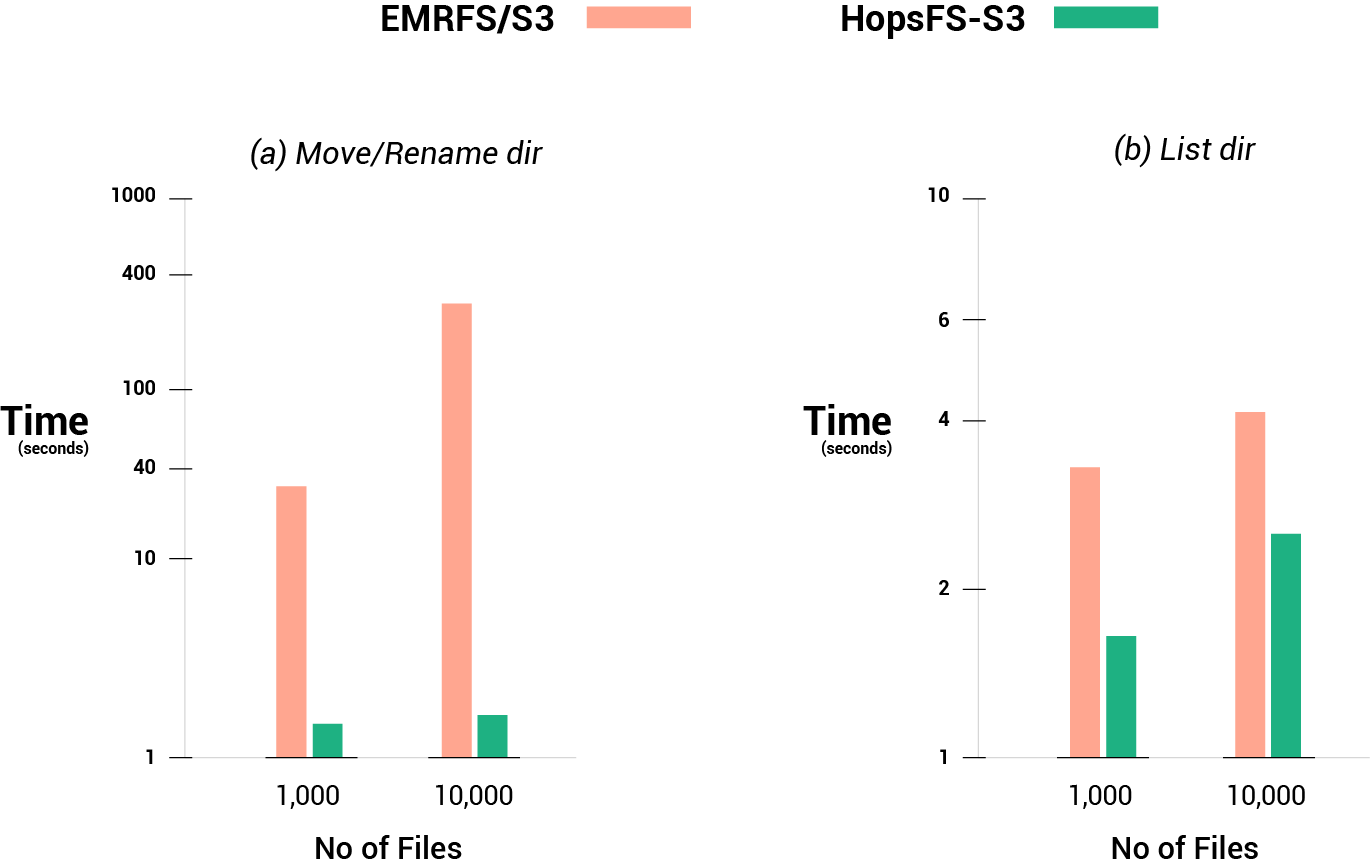
Moreover, we demonstrate that metadata operations on HopsFS (such as directory rename or file move) are up to two orders of magnitude faster than EMRFS. Finally, HopsFS opens up the currently closed metadata in S3, enabling correctly-ordered change notifications with HopsFS’ change data capture (CDC) API and customized extensions to metadata.
At Hopsworks, we have leveraged HopsFS’ capabilities to build the industry’s first feature store for machine learning (Hopsworks Feature Store). The Hopsworks Feature Store is built on Hops Hive and customized metadata extensions to HopsFS, ensuring strong consistency between the offline Feature Store, the online Feature Store (NDB Cluster), and data files in HopsFS.
Some of the key advantages of HopsFS/S3 are:
POSIX-Like Semantics with a HDFS API
- Consistent file listings, consistent read-after-write, atomic rename (files/directories).
Open, Extensible Metadata
- XAttr API to attach arbitrary metadata to files/directories.
Change Data Capture API
- Correctly ordered stream of file system mutation events delivered with low latency to downstream clients by ePipe.
Free-Text search API for File System Namespace
- File system namespace metadata changes can be transparently replicated to Elasticsearch for low-latency free-text search of the namespace and its extended metadata. This service is provided by Hopsworks.
X.509 Certificates for Authentication, TLS for Encryption-in-Transit
- HopsFS uses X.509 Certificates to identify and authenticate clients, with TLS providing end-to-end encryption-in-transit.
Faster Metadata Operations
- File/directory rename/move, file listings - no limit on retrieving 1000 files-at-a-time (as in S3).
Faster Read Operations
- Workers in HopsFS securely cache file blocks on behalf of clients using local VM storage. NameNodes are cache-aware and redirect clients to securely read the cached block from the correct worker.
Highly Available across Availability Zones (AZs)
- Support for high availability (HA) across AZs through AZ-aware replication protocols.
HopsFS/S3 Performance
We compared the performance of EMRFS instead of S3 with HopsFS, as EMRFS provides stronger guarantees than S3 for consisting listing of files and consistent read-after-updates for objects. EMRFS uses DynamoDB to store a partial replica of S3’s metadata (such as what files/directories are found in a given directory), enabling faster listing of files/dirs compared to S3 and stronger consistency (consistent file listings and consistent read-after-update, although no atomic rename) .
Here are some selected results from our peer-reviewed research paper accepted for publication at ACM/IFIP Middleware 2020. The paper includes more results than shown below, and for writes, HopsFS is on-average about 90% of the performance of EMRFS - as HopsFS has the overhead of first writing to workers who then write to S3.
HopsFS has a global worker cache (if the block is cached at any worker, clients will retrieve the data directly from the worker) for faster reads and the HopsFS’ metadata layer is built on NDB cluster for faster metadata operations.

*Enhanced DFSIO Benchmark Results with 16 concurrent tasks reading 1GB files. For higher concurrency levels (64 tasks), the performance improvement drops from 3.4X to 1.7X.
**As of November 2020, 3500 ops/sec is the maximum number of PUT/COPY/POST/DELETE per second per S3 prefix, while the maximum number of GET/HEAD requests per prefix is 5500 reads/sec. You can increase throughput in S3 by reading/writing in parallel to different prefixes, but this will probably require rewriting your application code and increasing the risk of bugs. For HopsFS (without S3), we showed that it can reach 1.6m metadata ops/sec across 3 availability zones.
In our paper published at ICDCS, we measured the throughput of HopsFS when deployed in HA mode over 3 availability zones. Using a workload from Spotify, we compared the performance with CephFS. HopsFS (1.6M ops/sec) reaches 2X the throughput of CephFS (800K ops/sec) when both are deployed in full HA mode. CephFS, however, does not currently support storing its data in S3 buckets.
How do I get started with HopsFS?
HopsFS is available as open-source (Apache V2). However, cloud-native HopsFS is currently only available as part of the hopsworks.ai platform. Hopsworks.ai is a platform for the design and operation of AI applications at scale with support for scalable compute in the form of Spark, Flink, TensorFlow, etc (comparable to Databricks or AWS EMR).
You can also connect Hopsworks.ai to a Kubernetes cluster and launch jobs on Kubernetes that can read/write from HopsFS. You connect your cluster to a S3 bucket in your AWS account or on Azure to a Azure Blob Storage bucket. You can dynamically add/remove workers to/from your cluster, and the workers act as part of the HopsFS cluster - using minimal resources, but reading/writing to/from S3 or ABS on behalf of clients, providing access control, and caching blocks for faster retrieval.