Feature Store Benchmark Comparison: Hopsworks and Feast
A comparison of the online feature serving performance for Hopsworks and Feast feature stores, contrasting the approaches to building a feature store.

Introduction
In the realm of machine learning, models learn from data and make predictions or decisions based on new inputs. When these trained models are transitioned into production, depending on the use case, the predictions on models can happen in two distinct modes, offline (batch mode) or online (real-time).
In online machine learning systems, users expect low latency predictions ( real-time predictions is where we guarantee responses lower than some upper bound). Among the most time consuming and computationally intensive operations for real-time machine learning is retrieving precomputed features from an online feature store.
The performance of online features retrieval can have a significant impact on the user experience. Low read latency and high throughput are essential for online feature retrieval, as they ensure that the model has fast access to fresh and consistent features for each input, thereby improving the overall performance of serving predictions to clients.
This article presents a performance benchmarking experiment assessing the online feature retrieval latency of the Hopsworks Feature Store using Locust - an open-source load testing framework in Python. Results were compared to Feast open-source feature store, based on a detailed performance benchmarking blog written for Feast’s website.
Disclaimer: As of November 2023, Feast feature store no longer has a commercial company backing the development of the open-source project, thus you could argue this benchmark is mute. However, Feast has wide adoption, and we believe this article can help inform users of performance characteristics of Feast
Performance of Online ML systems
Based on how the predictions of models are utilized, there are two main types of ML systems: offline and online ML systems. In batch ML systems, predictions are made in scheduled batch applications, where the model is applied to a large batch of input data and predictions are stored in some downstream datastore for later consumption.
Online predictions are made in real time, where the model is applied to a single or small set of data that is generated and consumed continuously. Online predictions are typically used for tasks that require instant feedback, such as in recommendation systems or financial fraud detection.
A key performance indicator for feature stores is the latency of online feature serving - the time taken to retrieve features for a given input. Low read latency is crucial for online predictions, as it directly affects the user experience and might be critical in some use cases like fraud detection systems. Thus, maintaining low read latency in a feature store is crucial.
Performance Benchmarking Online Feature Serving Latency
In our experiments, we used the Locust framework to carry out different load tests to measure the latency for online feature serving of Hopsworks Feature Store. We can define the user behavior and configure the testing for different parameters such as the number of concurrent users, spawn rate, time duration of tests etc. We used Locust as it is a highly scalable and configurable framework. The Hopsworks Feature Store API already supports testing the online feature serving API with Locust.
The Locust test framework evaluates and reports many metrics such as the number of requests per second, percentile latencies in milliseconds, failures, etc. The metric that we report in our performance benchmarking experiment is the 99th percentile latency for reads, also known as P99 read latency. P99 latency is the latency that 99% of the request requests are below, and it represents the worst-case scenario for online feature retrieval, inclusive of the slowest requests. Therefore, we report the P99 latency results as part of the benchmarks.
We tested Hopsworks Feature Store online read performance with the same methodology adopted by Feast feature store, so that we can compare the results in a consistent way. Feast online read performance is already well documented as part of the blog already released here.
Experiment Setup
We evaluated the performance using similar test environments and conditions so that the comparison is consistent with the Feast feature store benchmarking methodology. The Locust client was run on a virtual machine (VM) on Amazon Web Services (AWS) using Elastic Compute Cloud (EC2) instance type c5.4xlarge (16 vCPU, 32 GB memory). The locust client VM was in the same region as the cluster database nodes, eu-north-1 in our case. The client VM setup was configured to be similar to the Feast experiment setup, although Feast reported to deploy 16 feature server instances in their client VM whereas a single Locust client was run with multiple Locust users. The tests were run in stable conditions without causing any overload on the client VM.
For running Hopsworks, we used a Hopsworks managed cluster deployed on AWS. The configuration of the Hopsworks cluster deployed on AWS and details are shown in Table 1. The head node is responsible for running the web-application management services, worker nodes are utilized for feature engineering whereas the RonDB nodes manage the database for online Feature Store. In our tests, the worker was mainly used while generating and ingesting features to Hopsworks, whereas the RonDB nodes handles the actual online database transactions. The API node is used for running the Locust client during testing. While the complete Hopsworks cluster requires multiple VMs to run for different services, the Feast Python server application does not need multiple VMs. However, the overall resources utilized while using Feast would additionally depend on the cloud database service provider. As these cloud databases are serverless and Feast did not mention about its database resource consumption, the compute resource utilized cannot be quantified for comparison.
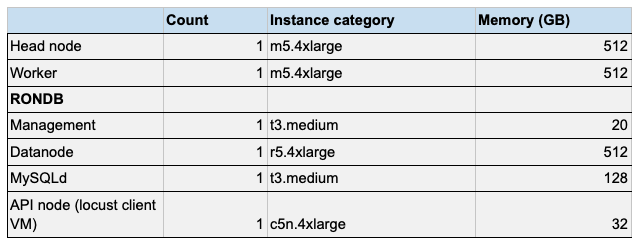
Table 1: Compute resources for managed Hopsworks cluster
Integrating Locust with Hopsworks Feature Store
We first created a Feature Group in Hopsworks and ingested a synthetic data frame containing random integers in the offline and online feature stores. The dimensions of the dataframe were 10K rows and 250 columns used as features, and an additional primary key column. Using this feature group we created Feature Views with different numbers of features, which we finally used for reading feature vectors from the locust tests. We used a constant throughput of 10 Requests per Second (RPS), although Hopsworks does not have a hard limit on the throughput rate for handling online queries and only depends on the cluster configuration.
Configuring the locust client to interact with the Hopsworks Feature Store can be easily done by changing the host parameters in a JSON file. We implemented a locustfile, which defines the user behavior we wish to test, and wrote tests for invoking get_feature_vectors API which is responsible for online feature serving in Hopsworks Feature Store. Note that we used the Python SDK for the Feature Store client, but Hopworks Feature Store also supports a Java SDK, which was not part of this experiment.
Results
We monitor the P99 latency from Locusts reports for the completion of the get_feature_vectors API call for reading feature vectors. The API also deserializes the retrieved features, therefore it is included in the read latency calculated by locust tests.Analysis for increasing number of featuresThe Hopsworks Locust tests iterations were run using different parameters. In the first test, we kept the batch size of the feature vector to read fixed at 1 entity row (meaning a single feature vector), and gradually increased the number of features in the vector from 50 to 250. We set a constant throughput of 10 RPS in the locust test file, spawning a single locust user. We ran the Locust test for 5 minutes.
We compared the performance of Hopsworks with the benchmark results as reported by Feast.The P99 latencies measured in milliseconds are summarized in Table 2. Fig. 1 shows the comparison of the latencies as a chart for better visualization.
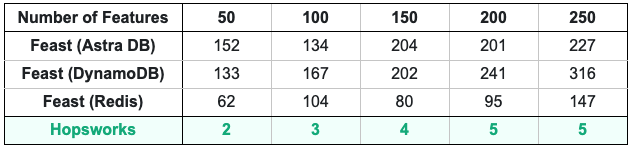
Table 2: Online read latencies (ms) for increasing features from 50 to 250 for Hopsworks and Feast
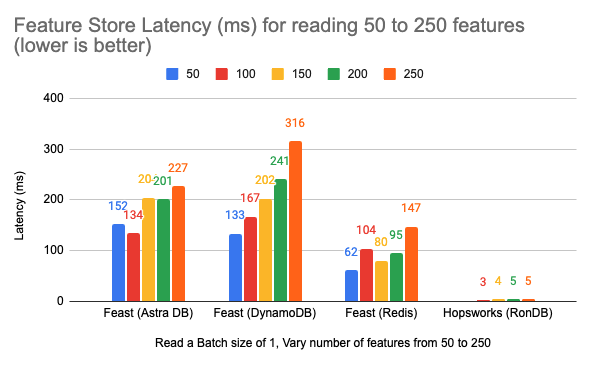
Figure 1: Feature vector retrieval latencies for Feast and Hospworks for increasing features size from 50 to 250 with constant batch size of 1.
Analysis for Increasing Request Batch Size
In the second scenario, we kept the number of features to read fixed at 50 and increased the batch size of feature vectors to read from 1 to 100. We kept the throughput and number of concurrent Locust users to 10 RPS and 1 respectively, and ran the test for 5 minutes. Redis was the fastest datasource in the benchmarks reported by Feast feature store so to simplify we only compare the results with the latencies for Redis. Table 3 shows the P99 latencies in milliseconds for Hopsworks and Feast (Redis). Figsummarizes the comparison as a chart for better visualization.

Table 3: Online read latencies for increasing batch size from 1 to 100 (ms) for Hopsworks and Feast(Redis)
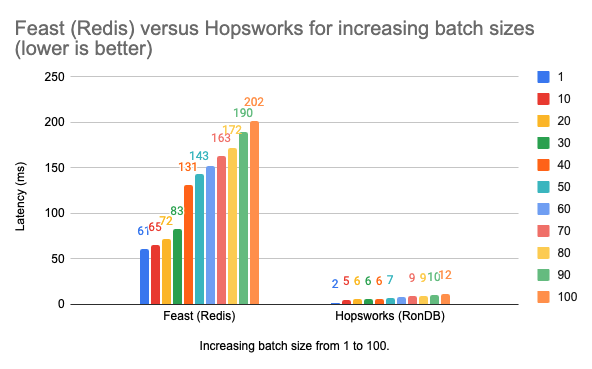
Figure 2: Feature vector retrieval latencies (ms) for Feast (Redis) and Hospworks for increasing batch size from 1 to 100 with constant features size of 50.
Lastly, we also ran the test with 70 features, to compare it with performance of the Cassandra plugin for Feast. We increased the number of locust test users to 50 by using the distributed mode of Locust by running it in multiple Docker containers. For more information on how to run locust in Docker containers, check the Locust documentation. The tests were run for 5 minutes each for batch size 1 and 30. Results are shown in Table 4 below.
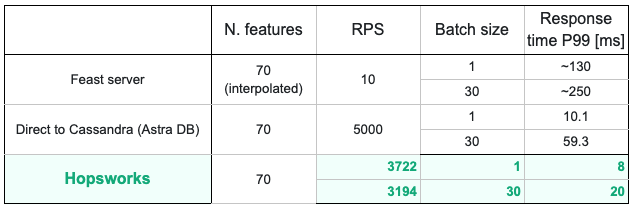
Table 4: Online read latencies (ms) comparison with Feast (Cassandra) and Hopsworks for fixed feature size of 70
As we can see from the results, P99 latencies reported by locust tests for Hopsworks were the lowest for all of the scenarios. The feature vector read latency increases linearly when the number of features or batch size is increased, although the magnitude of change is small and not drastic.
Performance as a Function of Architecture
One of the important reasons for this difference in latencies is the architecture and implementation of the feature stores. Feast feature store lacks a built-in database, but instead integrates to different database sources, like Redis and Cassandra. It uses a Python Feature Server to query the database, which adds an extra layer of communication and processing. Note, that Feast also supports a Java server, which is claimed to be faster than Python, but currently is not part of the benchmarking experiments released by Feast. Hopsworks, on the other hand, is built on top of RonDB, a key-value database with a MySQL API and a REST API. RonDB is currently the world’s fastest key-value store which is extensively benchmarked in previous blogs. Hopsworks leverages an in-built query engine in Python that can directly query RonDB using either its MySQL API or REST API. A high level architecture of the Hopsworks Online Feature Store is shown in the Figure below.
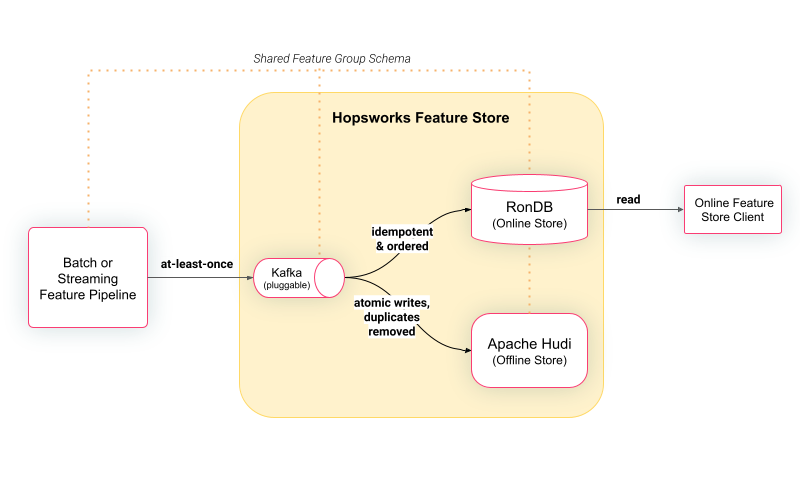
Figure 3: High level overview of how clients write to Hopsworks Online Feature Store architecture with RonDB as the Online Feature Store. Online clients read precomputed features to build rich feature vectors for online models.
Summary
We introduced how Locust load testing framework can be adopted for performance benchmarking online feature serving latencies in Feature Stores. In particular, we ran different tests for benchmarking Hospworks Feature store for measuring the latencies for online feature retrieval using its Python SDK. We compared the results of P99 latencies to Feast open-source feature store, based on its previously published benchmarks. The results indicate that Hopsworks performs with much lower read latency than Feast for online feature vector retrieval. This is attributed to Hopsworks architecture, as Hopsworks runs on a built-in key-value store, RonDB, which is also the fastest key-value store. Detailed performance benchmarking about the RonDB key-value store can be found here.
As part of the performance benchmarking work, we released extensive benchmarking methods for feature stores covering use cases such as offline read and write latencies, feature freshness (time taken for latest feature ingested to be available in online store) and online read latencies for different publicly available features. The results and code are available in the GitHub repo.
Choosing a feature store for one's needs requires careful consideration, including performance aspects. Feast feature store has many advantages, one of them being that it integrates with various data sources and platforms, and its large open-source community. The choice of the feature store depends on the specific requirements and preferences of the user and the application. Therefore, it is important to conduct a thorough and fair performance benchmarking of different feature stores, and to consider both the quantitative and qualitative aspects of each feature store. This blog aims to contribute to the development of open-source benchmarking tools for feature stores, fostering better standards within the community.