GenAI comes to Hopsworks with Vector Similarity Search
Consolidate your Data for AI in a Single Platform
Hopsworks has added support for approximate nearest neighbor (ANN) indexing and vector similarity search for vector embeddings stored in its feature store.

Introduction
Vector similarity search has gained wide adoption in recent years, with the growth of vector databases. That retail website that shows you similar items of clothing to the one you're viewing, or the personalized recommendation system that recommends products based on your recent browsing/purchasing history are examples of vector similarity search. From a database perspective, if you have a table containing rows of items, you can take one item and perform vector similarity search on the table and it will return rows of items semantically similar to your item. To perform vector similarity search, you need an embedding model to take your item data and compress it into a vector embedding. What’s different and new about vector embeddings is that they retain semantic information about an item even after compression.
Vector similarity search applications range across various domains, from RAG in LLMs, to recommendation systems, to image similarity search and beyond. As such, vector similarity search has become an important capability in operational machine learning systems where semantically related information can be retrieved at low latency. While vector similarity search originated with vector databases, other databases have recently added support for vector similarity search as a capability, including Postgres/pgvector, Neo4J, OpenSearch, Elastic, Datastax, and more. In this article, we discuss the addition of ANN indexes to feature groups in Hopsworks, enabling vector similarity search over feature groups stored in Hopsworks.
Vector Similarity Search for Feature Stores
Building ML systems is hard and production systems have traditionally had high operational cost. For example, personalized recommender systems based on the retrieval-and-ranking architecture have traditionally included a vector database, to generate candidates, a feature store, to enrich the candidates with features before ranking the candidates, and model-serving infrastructure to host the ranking model. That is a lot of infrastructure to operate.
Now, with its new vector similarity search capability, Hopsworks can now provide all the ML infrastructure needed to support use cases such as the retrieval-and-ranking recommender architecture, but also other use cases such as RAG and fine-tuning in a single platform.
Extending Feature Groups with ANN Indexes
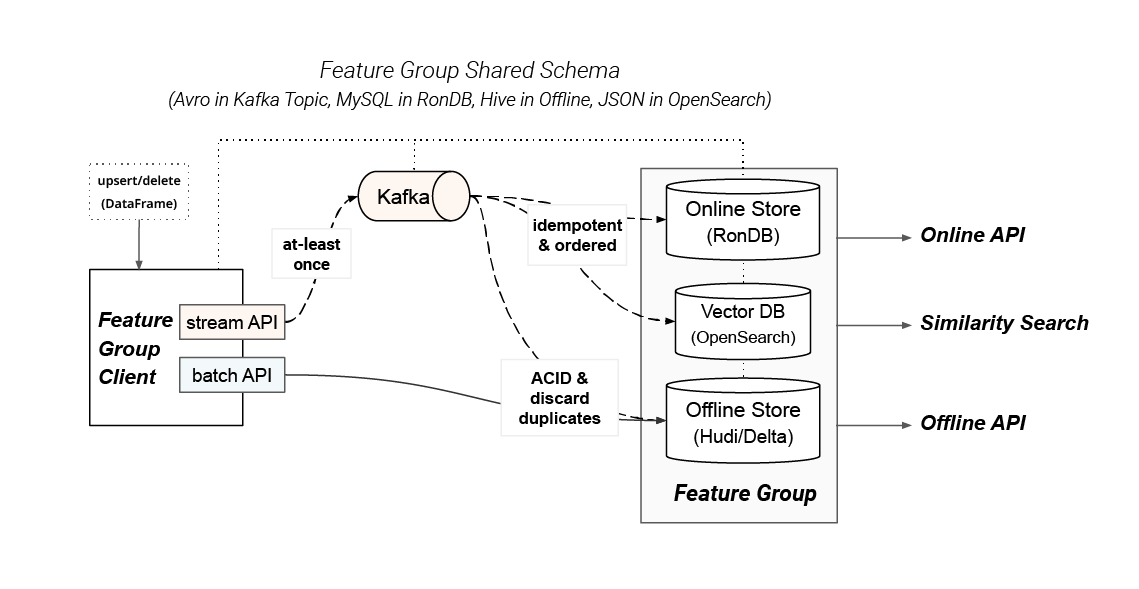
Figure 1: Feature Group Shared Schema
Hopsworks provides a Feature Group API for writing DataFrames (Pandas, Polars, or Spark) transparently to either the offline, online, or both stores. The Feature Group client has internal batch and stream APIs for routing the data to the backend stores.
The code snippet below shows how to create a Feature Group with a DataFrame, where the content column contains vector embedding data that should be indexed for vector similarity search. Vector embeddings are only supported in online-enabled Feature Groups. Under the hood, DataFrame is written to Kafka and synchronized to the backend stores: RonDB (online), Opensearch (vector DB), Apache Hudi or Delta Lake (offline store). Hopsworks transparently creates a unified schema for all of these stores, manages the lifecycle (creation/deletion) of the backing tables/indexes, and optimizes their layout for query performance.
Now, when you write your vector embedding data to a Feature Group, you get additional benefits above and beyond what is found in existing vector databases:
- transparent data validation on data ingestion, through declarative support for Great Expectations data validation rules,
- time travel support for feature groups, crucial for exact reproduction of training datasets using only metadata,
- training dataset creation using vector embeddings (this is particularly important for time-series data, where temporal joins are needed to create point-in-time correct training data),
- efficient retrieval of vector embeddings along with feature data using Hopsworks Feature Query Service.
The upshot of these improvements is that you can treat your vector embeddings as any other data source for AI with Hopsworks Feature Store. You get all the benefits of a feature and vector database in a single platform.
Vector Similarity Search API
The vector similarity search API is designed for ease of use, enabling developers to seamlessly integrate similarity search into their applications. Users provide the target embedding as a search query to a feature group as well as a nearest neighbor count k, and it returns k rows of features that contain the approximately closest embedding vectors from the feature group. You can also provide a filter that is pushed down to the vector database, filtering out unwanted rows.
For creating training datasets using historical embeddings with point-in-time correctness, a feature view provides methods to create training dataset with or without time split.
To retrieve feature data at a specific time in the past from the feature group, users can utilize the offline read API to perform time travel.
Personalized Recommendations with Retrieval and Ranking
We have a complete personalized recommendations example, based on the Retrieval and Ranking architecture, available in our tutorials to help get you started with using vector similarity search.
In the retrieval and ranking architecture, the second phase reranking of the top k items fetched by first phase filtering is common where extra features are required from other sources after fetching the k nearest items. In practice, it means that an extra step is needed to fetch the features from other feature groups in the online feature store. Hopsworks provides yet another simple read API for this purpose. Users can create a feature view by joining multiple feature groups and fetch all the required features by calling fv.find_neighbors. In the example below, view_cnt from another feature group is also returned in the result.
Summary
In this blog, we have introduced the enhanced vector similarity search capabilities in Hopsworks. Explore the notebook example, demonstrating how to use Hopsworks for implementing a news search application. Users can search for news using natural language in the application, powered by the new Hopsworks vector database.