From 100 to ZeRO: PyTorch and DeepSpeed ZeRO on any Spark Cluster with Maggy
Use open-source Maggy to write and debug PyTorch code on your local machine and run the code at scale without changing a single line in your program.

Distributed learning - An introduction
Deep learning has seen a surge in activity with the availability of high level frameworks such as PyTorch to build and train models. A few lines of code in a notebook are sufficient to create powerful classifiers from scratch. However, both the data and model sizes to achieve state-of-the-art performance are ever increasing, so that training on your local GPU becomes a hopeless endeavour.
Enter distributed training. Distributed training allows you to train the same model on multiple GPUs on different shards of your data to speed up training times. In the ideal case, training on 4 GPUs simultaneously should reduce your training time by 75%. In distributed training, each GPU computes a forward and backward pass over its own batch of the data. For the model update, the computed gradients are shared and averaged between the nodes. This way, all models update their parameters with the same combined gradient and stay in sync. This additional communication step introduces additional overhead of course, which is why ideal scaling is never truly achieved.
So if distributed training is such a great tool to accelerate training, why is its use still uncommon among normal PyTorch users? Because it is too tedious to use! A dummy example for starting distributed training might look something like this.
Going even further, you would need to launch your code on all of your nodes and take care of graceful shutdowns and collecting the results. This is where Maggy comes in. Maggy allows you to launch your PyTorch training script without any changes on Spark clusters. It takes care of the training processes for each node, the resource isolation and node connections.
Next we will explore what is needed to run distribution transparent training on Maggy as well as the restrictions that still exist with the framework.
Building blocks for distribution transparent training
Configuring Maggy
First of all, Maggy requires its experiment to be configured for distributed training. In the most common use case this means passing your model, hyperparameters and your training/test set. Configuring is as easy as creating a config object. Hyperparameters, train and test set are optional and can also be directly loaded in the training loop. If your training loop consists of more than one module such as in training GANs with a Generator and Discriminator or Policy gradient methods in RL, you can also pass a list of modules.
Writing the training function
Maggy’s API requires the training function to follow a unified signature. Users have to pass their model class, its hyperparameters and the train and test set to the training function.
If you want to load your datasets on each node by yourself, you can also omit passing the datasets in the config. In fact, this is highly recommended when working with larger dataset objects. Additionally, every module used in the training function should be imported within that function. Think of your training function as completely self contained. Last but not least, users should use the PyTorch DataLoader (as is best practice anyways). Alternatively, you can also use Maggy’s custom PetastormDataLoader to load large datasets from Petastorm parquet files. When using the latter, users need to ensure that datasets are even, that is they should have the same number of batches per epoch on all nodes. When using PyTorch’s DataLoader, you do not have to care about this. So to summarize, your training function needs to
- Implement the correct signature
- Import all used modules inside the function
- Use the PyTorch DataLoader (or Maggy’s PetastormDataLoader with even Datasets)
Distributed training on Maggy - A complete example
It’s time to combine all the elements we introduced so far in a complete example of distributed training with Maggy. In this example, we are going to create some arbitrary training data, define a function approximator for scalar fields,write our training loop and launch the distributed training.
Generate some training data
In order to not rely on specific datasets, we are going to create our own dataset. For this example, a scalar field should suffice. So first of all we randomly sample x and y and compute some function we want our neural network to approximate. PyTorch’s TensorDataset can then be used to form a proper dataset from this data.
Define the approximator
Next up we define our function approximator. For our example a standard neural network with 3 layers suffices, although in real applications you would of course train much larger networks.
Writing the training loop
At the heart of every PyTorch program lies the training loop. Following the APIs introduced earlier, we define our training function as follows.
As you can see, there is no additional code for distributed training. Maggy takes care of all the necessary things.
Starting the training
All that remains now is to configure Maggy and run our training. For this, we have to create the config object and run the lagom function.
Evaluating the training
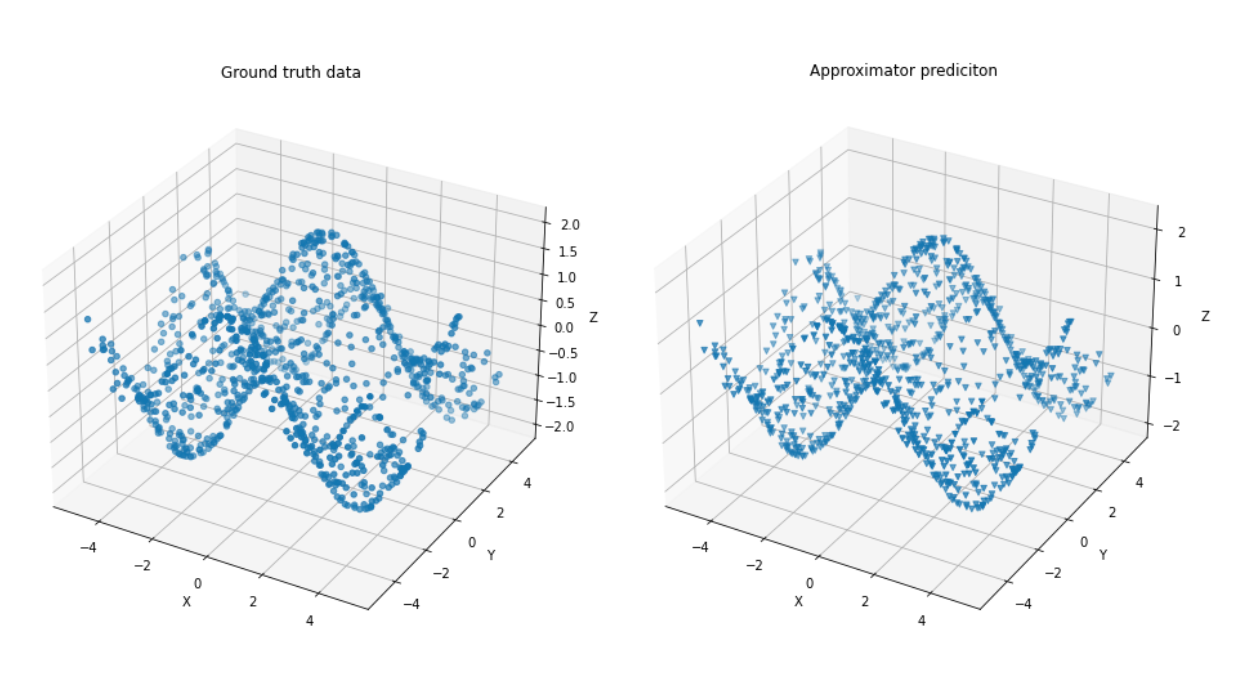
After running the training on 4 nodes, we can see that our approximator has converged to a good estimate of our scalar field. Of course, this would also be possible on a local node. But with more complex models and larger training sets such as the ImageNet dataset, distributed learning becomes necessary to leverage your workloads.
Try it for yourself
Maggy is open-source and documentation is available at maggy.ai. Give us a star or get in touch if you have more questions. Maggy is also available for all Hopsworks users in the managed platform on AWS or Azure. You can get started for free (no credit card required).