Reproducible Data for the AI Lakehouse
Reproducible Training Data for AI requires Ingestion Time, not Event Time
We present how Hopsworks leverages its time-travel capabilities for feature groups to support reproducible creation of training datasets using metadata.

This article is part 7 in a 7 part series describing in lay terms concepts and results from a SIGMOD 2024 research paper on the Hopsworks Feature Store.
Other Parts: 1 (Modular/Composable AI Systems) , 2 (The Taxonomy for Data Transformations), 3 (Use all features: Snowflake Schema) , 4 (Lakehouse for AI), 5 (Arrow from Lakehouse to Python), 6 (Real-Time AI Database).
Introduction
Data science has aspired to be more science than engineering, with an emphasis on reproducibility and replicability as they are cornerstones of the scientific method. This has led to the growth in popularity of experiment tracking platforms that store hyperparameters from training runs to enable models to be reproduced from metadata. Model registries are also providing the same capability, storing model training hyperparameters and assets such as loss curves, model validation model bias reports.
In contrast, reproducible training data has received comparatively less attention. This is surprising, considering the recent growth in data-centric AI - particularly in the training and fine-tuning of large language models (LLMs), where the quality and size of training datasets has been the dominant factor in their performance. In this article, we present how Hopsworks leverages its time-travel capabilities for feature groups to support reproducible creation of training datasets using metadata. Hopsworks currently is the only feature store platform to support reproducible training datasets, an important capability not just for data-centric AI, but also with increased regulation coming soon to AI.
Data-Centric AI
AI has traditionally been concerned with model-centric approaches to improving model performance. For example, a data scientist would change the hyperparameters or model architecture, retrain the model and evaluate the performance. This process of making changes in hyperparameters, retraining and evaluating, continues iteratively until the model passes all performance and validation checks.
Data-centric AI is an alternative approach to improving the performance of AI systems that involves making changes to the data used to train the models, rather than the hyperparameters or model architecture. A data scientist changes the features or set of samples in a training dataset, retrains the model, evaluates its performance and performs model validation checks. You can, of course, combine model-centric and data-centric approaches when developing AI systems.
One challenge facing adoption of data-centric AI is how to reliably reproduce training datasets. Before data-centric AI, training datasets have been assumed to be immutable and always available. Many enterprises have to keep training data - or be able to reliably reproduce it - for compliance.
Data-centric AI is an iterative process, and it may involve creating as many as 10s or 100s or even 1000s of training datasets before the model passes its performance and validation checks. For model-centric AI, keeping 100s or 1000s of experiment tracking details is feasible, as it involves only storing a few KBs of metadata. For data-centric AI, storing 100s or 1000s of training datasets is often infeasible - either economically or practically. The training datasets are just variants from the same data sources, with either different feature engineering steps or different ranges of samples or different sets of features. Is it possible to keep the data sources, and just store the metadata used to create the training datasets from those data sources? Yes, with help from the Hopsworks feature store.
Creating Training Data from Mutable Data Sources
Training data for machine learning models is often created from dynamic data sources. Prediction problems at Enterprises, from fraud to recommendations to any time-series prediction, involve new data that arrives at some cadence - once per week, day, hour, or continually in a stream.
In Hopsworks, feature groups are tables that store mutable data. Each update to a feature group is defined by a commit - an atomic update to the data stored in that feature group, see figure 1. Feature groups have time-travel capability - you can read the state of the feature group by providing the commit timestamp as a parameter and it will return the state of the feature group as of that point-in-time.
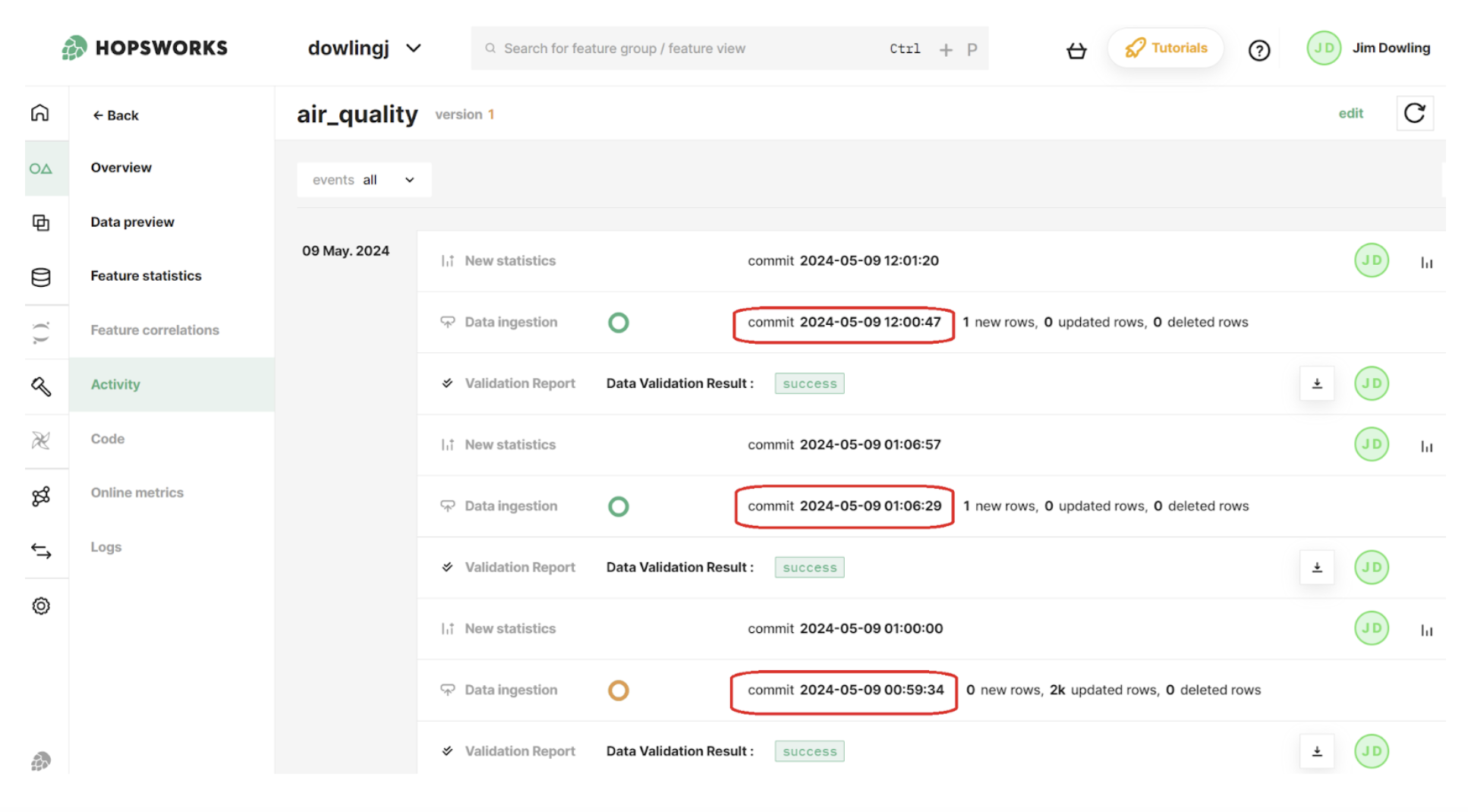
Figure 1: In the Air Quality Feature Group UI, there is an Activity tab that shows the commits to the feature group, including the rows updated/deleted/appended and whether the data ingestion passed the data validation tests or not.
In Hopsworks, when you read training or inference data from feature groups, you first create a feature view - the selection of features (and labels) that you will use in your model. The feature view prevents training-inference skew, by enforcing the same schema for the model in both training and inference, and also prevents future data leakage or stale data in training datasets by implementing a temporal join when creating training data that spans 2 or more feature groups.
To illustrate the challenge of reproducible training dataset creation, we provide a motivating example (from Building AI Systems with a Feature Store by O’Reilly) where feature data is stored in two feature groups - one storing weather data, the other storing air quality data. Each feature group has an event_time column which stores the timestamp when the measurements were made - e.g., this weather measurement was observed on 20th April 2024 or this pm2.5 air quality was measured on 20th April 2024. The commits to these feature groups are not, however, viewable as a column (e.g., a timestamp column) in Hopsworks feature groups. Instead, they are managed internally by Hopsworks (hidden columns). Hopsworks provides time-travel APIs to query data from a feature group for a given commit or a range of commits.
In Figure 2, below, we can see that weather data and air quality data measurements arrive once per day for our feature groups. However, there is a gap in the air quality data for 6 days, and then all of its measurements arrive on the 7th day. A Training Dataset v1 was created on day 6 and didn’t include the air quality measurements for the previous six days.
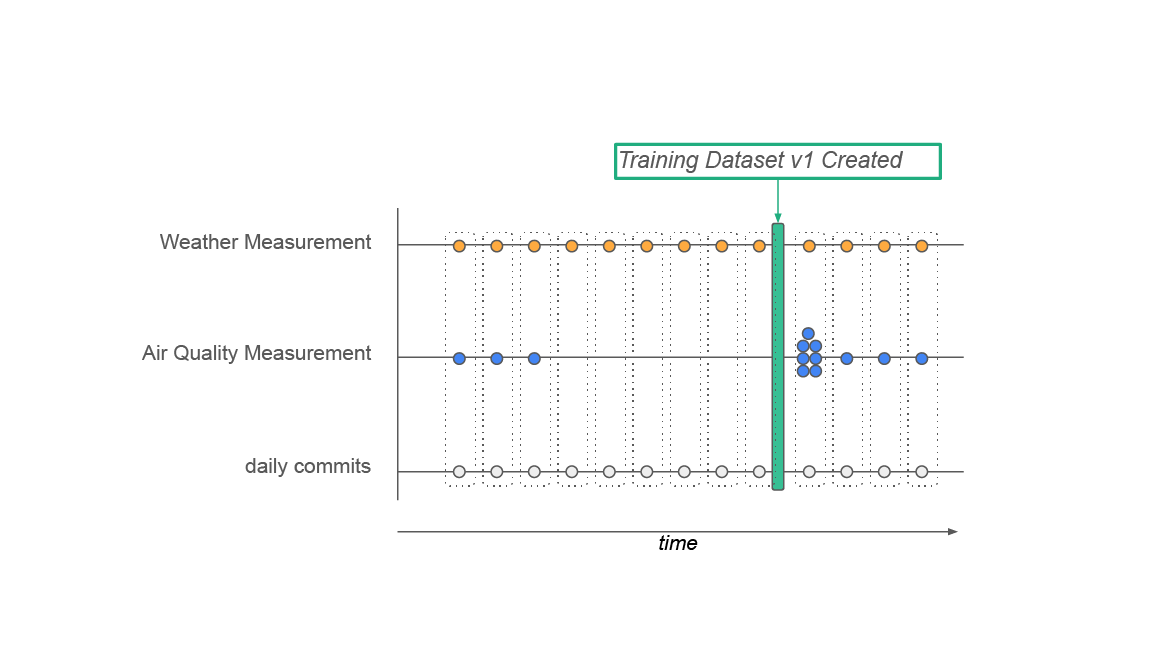
Figure 2: In this diagram, we see air quality measurements missing for 6 consecutive days, then they all arrive late on day 7. A Training Dataset v1, containing both weather and air quality data, was created just before the late. Time-travel support and the daily commits enable us to accurately recreate Training Dataset v1 at a later point in time - we need to recreate it without the late arriving data (it should be exactly as when it was created).
If we delete Training Dataset v1 and want to reproduce it at a later point in time, we should not include the late arriving data in it, as it was not included in the original version. Instead, we can use the daily commits data to reproduce Training Dataset v1 ASOF the point in time when it was created.
In Python code, we run the following snippet to create a training dataset as a Pandas DataFrames and then at any point later in time, recreate it using only its training dataset ID and the feature view object used to create it:
In Python code, we run the following snippet to create a training dataset as files. We can later delete the files (for example, to reclaim disk space) and then at any point later in time, recreate it using only its training dataset ID and the feature view object used to create it:
In Hopsworks, filters that are applied to create training datasets are also stored as metadata, so that they can be used for reproducible training dataset creation:
In the above example, we want to train and make predictions using our feature view - but only for users whose region is the ‘US’. For this, we apply the filter “region=’US’” when we create the training dataset. The filter is stored as metadata along with the training dataset, and when we later use the feature view to get batch inference data, we initialize the feature view to the correct training dataset version, so it knows which filters to apply. Typically, you can safely omit the command fv.init_batch_serving(training_dataset_id=td_id) if we store the feature view object along with the model in the model registry. The feature view (and the training dataset version) can be saved in Hopsworks model registry along with the model. When you download the model for inference (batch inference or online inference), you can retrieve the feature view object for that model, and the model will, by default, transparently set the training_dataset_id for the feature view before returning it.
Summary
Reproducible data is crucial for AI systems, not just for model training but also for the data used in inference. Hopsworks ensures that training datasets can be accurately recreated, even when the training data has been deleted and the data sources are dynamic and mutable. Reproducible training data is essential for compliance and a key enabling functionality for data-centric AI. Try out Hopsworks reproducible training data capabilities in this notebook - just register a free account first at run.hopsworks.ai.