RonDB: A Real-Time Database for Real-Time AI Systems
Push-them-down: Projections/Predicates/LEFT-JOINs/Aggregations
Learn more about how Hopsworks (RonDB) outperforms AWS Sagemaker and GCP Vertex in latency for real-time AI databases, based on a peer-reviewed SIGMOD 2024 benchmark.

This article is part 6 in a 7 part series describing in lay terms concepts and results from a SIGMOD 2024 research paper on the Hopsworks Feature Store.
Other Parts: 1 (Modular/Composable AI Systems) , 2 (The Taxonomy for Data Transformations), 3 (Use all features: Snowflake Schema) , 4 (Lakehouse for AI), 5 (Arrow from Lakehouse to Python).
Introduction
Many real-time AI systems make decisions based on information poor signals - a user swipe generates recommendations, a single credit card payment is checked for fraud, or network packet is evaluated for network intrusion. All of these systems make better decisions when they can augment the signal with historical and contextual information retrieved using one or more entity identifiers extracted from the weak signal - a user ID, a credit card number, or an IP traffic flow.
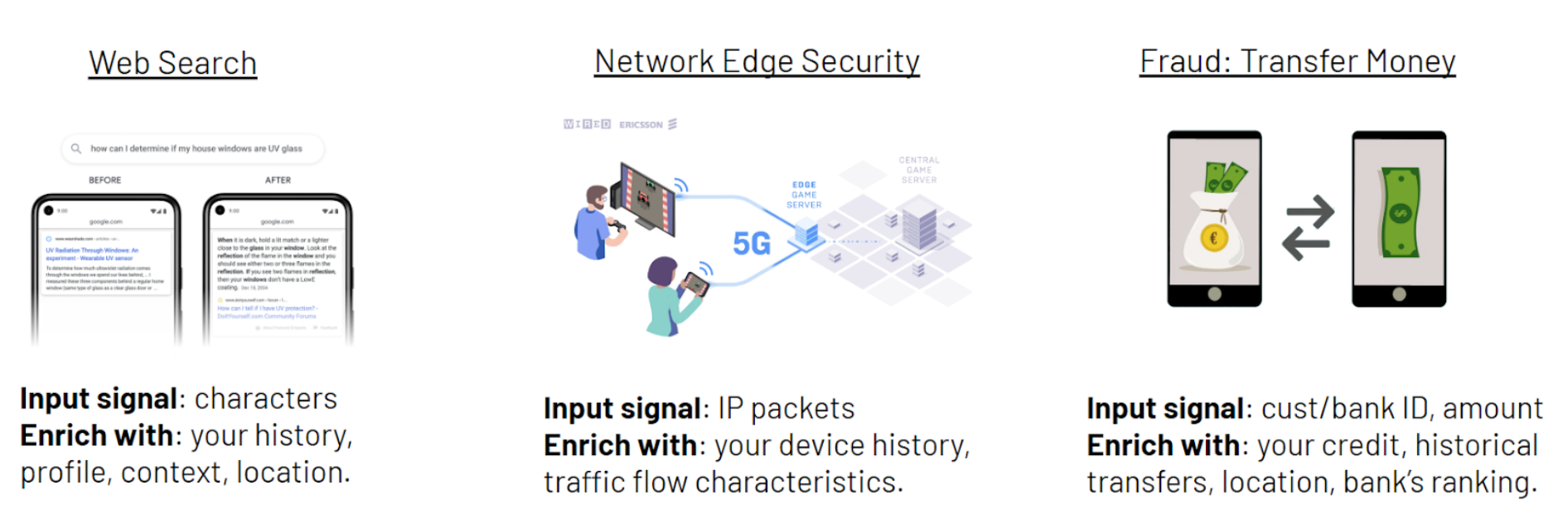
Figure 1. A real-time database can return historical and context features to a real-time AI system, enriching the prediction request with more information, enabling better predictions.
Real-Time AI Workloads
Databases connect models to data to turn weak signals and poor predictions into rich signals and high quality predictions. To do that, AI systems use entity IDs and other information to query databases to retrieve features that are used to build a feature vector (the input to the AI model). The AI systems typically have a SLO (service level objective) - the maximum amount of time between a prediction request and a prediction response. Within that prediction requests budget, you have both the time required to query the database, the time required to compute on-demand features (features computed using prediction request parameters), and the time to make the actual prediction using the AI model.
The database is only part of the total SLO for a real-time AI prediction request, so the main technical capability is support for low latency queries (and high throughput for larger systems). Those goals can be decomposed into many of the database capabilities for real-time AI systems shown in Table 1.
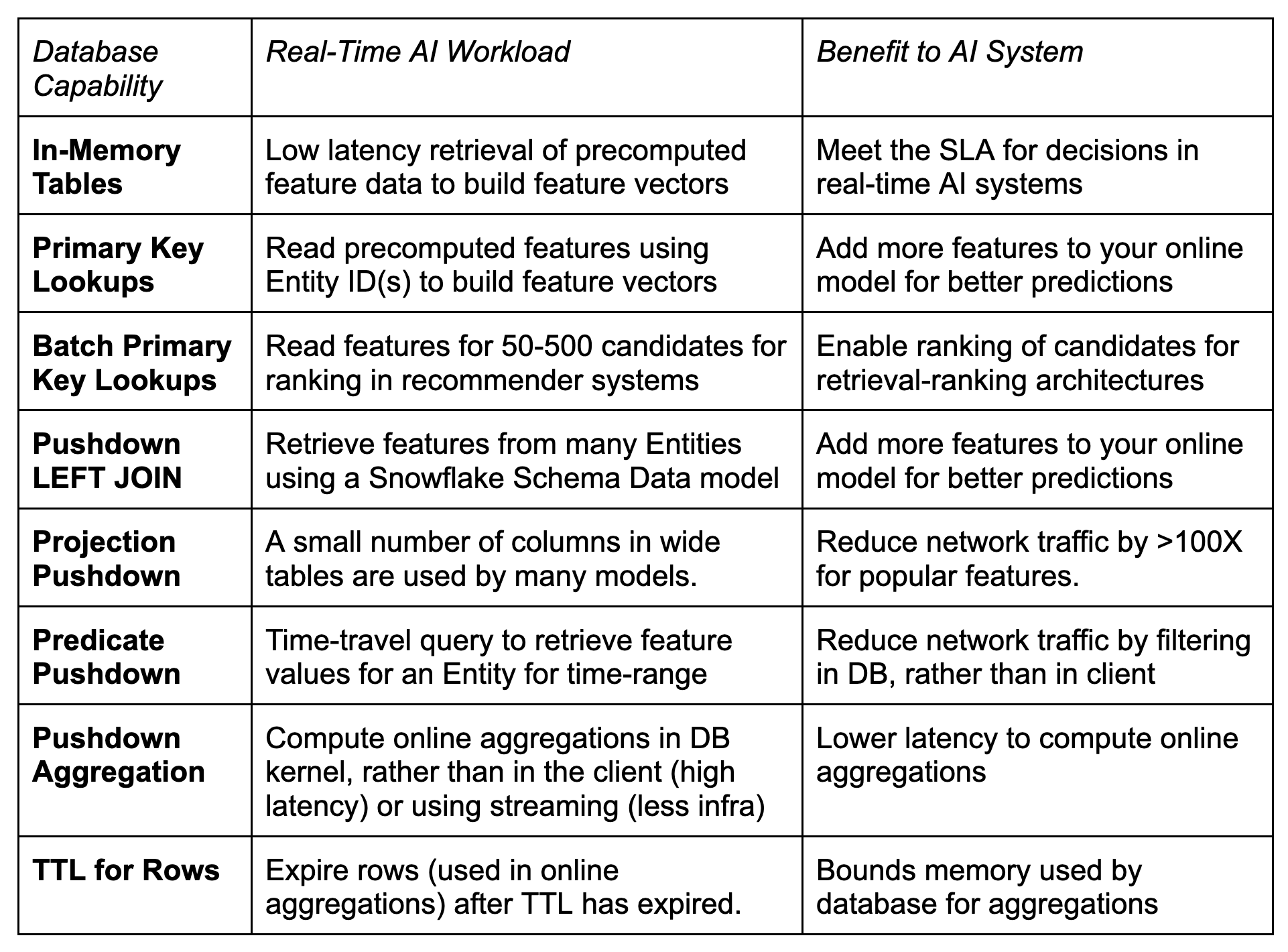
Table 1. Real-Time AI workloads, the database capabilities that meet them, and resulting benefit for the AI system.
In addition to the above database capabilities, the client that calls the real-time database to build feature vectors (the feature store client) should also be able to issue concurrent queries to separate tables for different entity keys, and, in parallel, build the complete feature vector used by the model. Hopsworks feature store client supports parallel queries for separate entity IDs, ensuring latency does not increase for an increasing number of entities (and feature groups) used by a model.
Table 2, below, compares the capabilities of the most popular databases for online feature stores (databases that power online real-time AI systems) - RonDB (Hopsworks), DynamoDB (Sagemaker, Tecton, Databricks), Redis (Feast, Tecton), and BigTable (Vertex). Here, we included some additional capabilities, such as the ability to support multi-part primary keys, and general SQL support (for custom use cases).
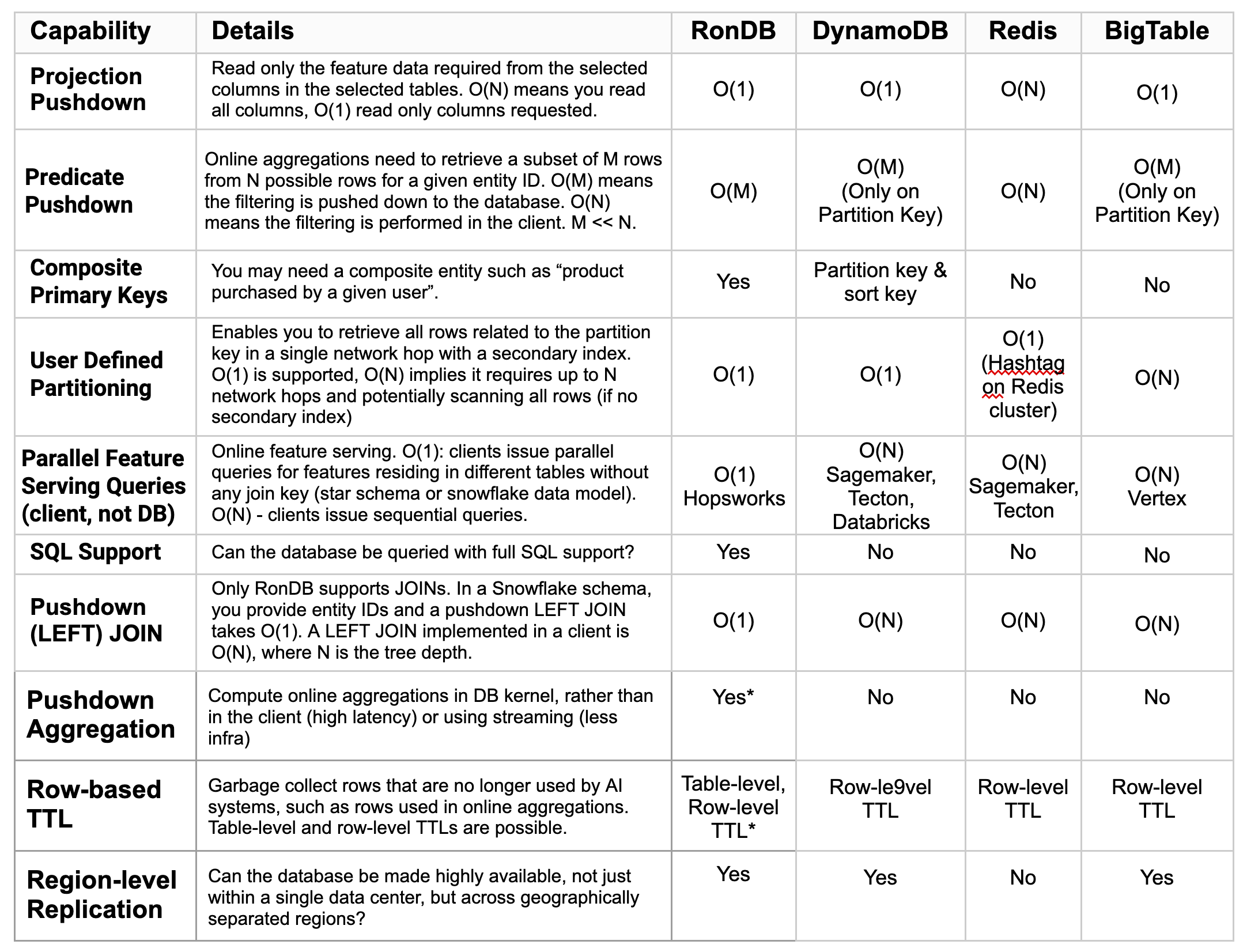
Table 2. Comparison of database and feature store client capabilities that are important for real-time AI workloads. RonDB (*24.10) is the only real-time database designed for real-time AI workloads. Other databases popular as online feature stores are DynamoDB, Redis, and BigTable.
SIGMOD Benchmark Results
Our published benchmark compared cloud-based feature stores that were publicly available. At the time of submission, Databricks online feature store was not available (it was only released in April 2024). However, Databricks also uses AWS DynamoDB as their preferred database, so the benchmark results for AWS Sagemaker will be broadly similar to Databricks. Google used BigTable at the time of publication submission, which is architecturally similar to DynamoDB.
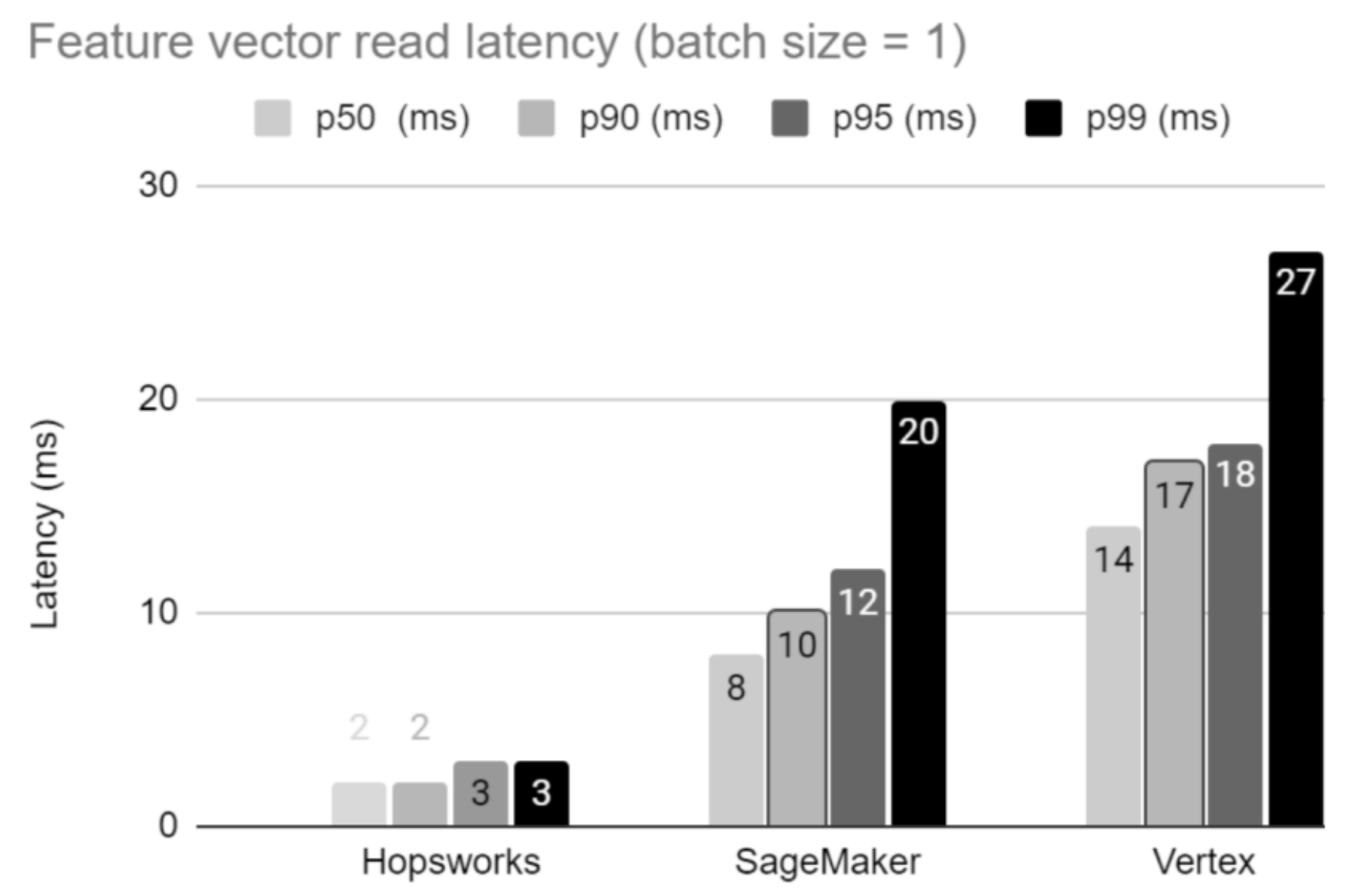
Figure 2. Hopsworks has almost an order of magnitude lower latency (p99) for reading a single feature vector compared to AWS Sagemaker and GCP vertex.
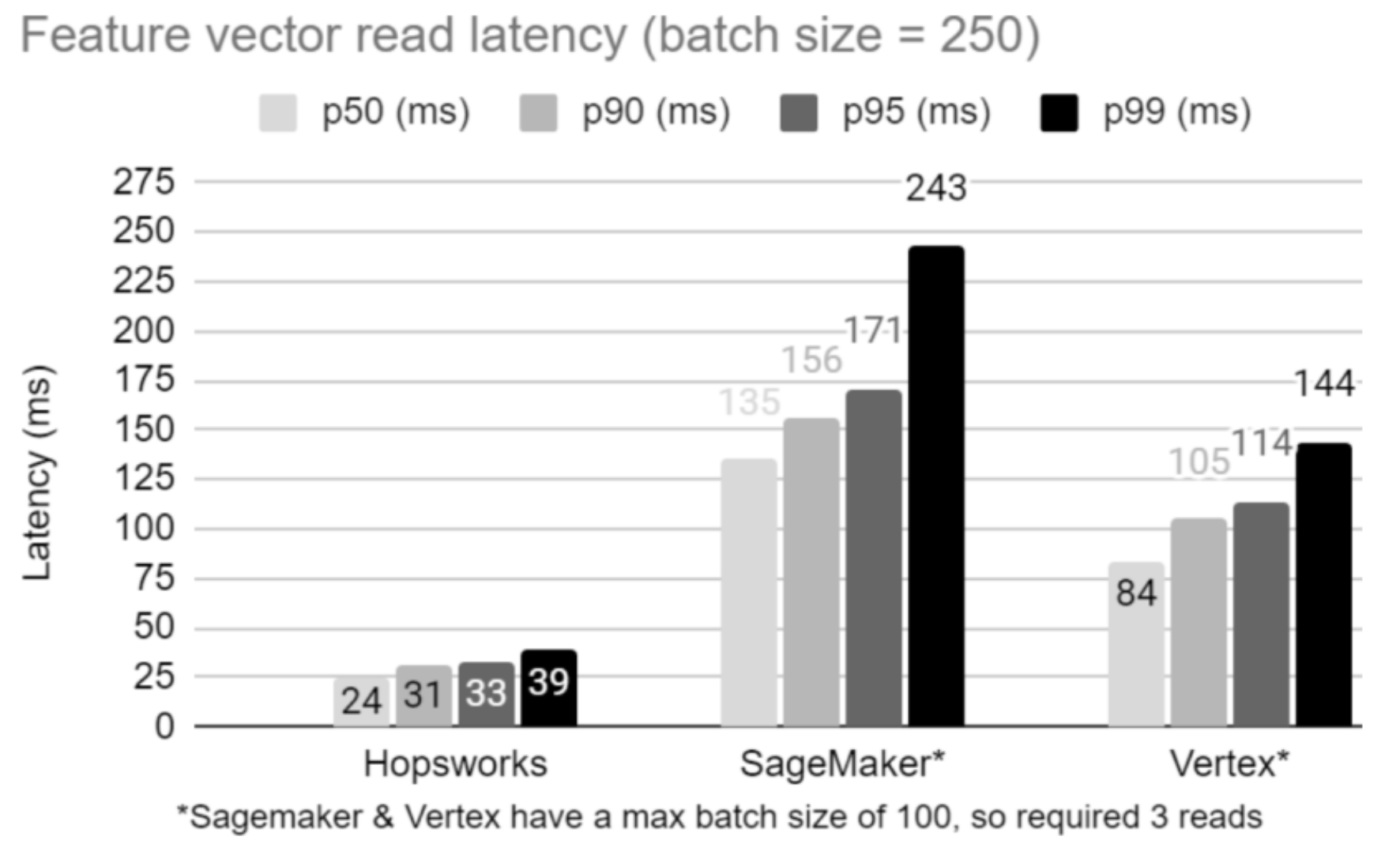
Figure 3. Batch primary key lookups are used heavily for the ranking step in AI recommender systems. Here, we can see that Hopsworks has almost an order of magnitude lower latency (p99) for reading a batch of feature vectors of size 250 rows compared to AWS Sagemaker. GCP Vertex results are better here than in practice, as their REST API did not deserialise the results, which would have cost many more milliseconds and is not included here.
The above benchmark results show the advantages of using an in-memory database, like RonDB (which also supports on-disk tables if you need them), that is engineered for low-latency workloads. Our benchmark is still a work in progress. We didn’t perform a comparative benchmark of pushdown LEFT JOINs in RonDB versus doing the LEFT JOINs in the feature store client for the other databases. We also didn’t publish benchmarks yet on the latency reduction in pushing down online aggregations to the database kernel, but we already see 5-6X reductions in latency, and when it is generally available in RonDB 24.10, we expect that performance to be even better.
Comparison with Redis
Although FEAST supports DynamoDB, AstraDB, and Redis, Redis has been the most popular choice of online store due to its low latency and ease of installation. Feast’s Redis support has many limitations, detailed in this open Github issue “Redis Online Store adapter is not production-ready”, including increasing latency for every table you add to your model and orphan tables in Redis even if you use Feast APIs to delete feature views.
However, many of the problems are with Redis itself, not just Feast’s use of Redis. Redis has been problematic for online scaling and online upgrades, so that DoorDash abandoned Redis, despite extensive customizations they made to Redis source code for their real-time AI workloads. Redis is missing core capabilities such as pushdown projections, predicate pushdowns, pushdown aggregations, and pushdown LEFT JOINs. Here is an earlier article that compares performance of Hopsworks with Feast and Redis.
Conclusions
Real-time AI Systems have unique and challenging workloads for databases and still have the same high availability, low latency, and high throughput requirements as existing operational systems. We designed RonDB to meet these challenges, with features such as pushdown projections/predicates/LEFT JOINs/aggregations. RonDB makes Hopsworks the highest performance online feature store that meets the most challenging AI system performance and availability requirements.