Using an External Python Kafka Client to Interact with a Hopsworks Cluster
Learn how to publish (write) and subscribe to (read) streams of events and how to interact with the schema registry and use Avro for data serialization.

This tutorial was tested using Hopsworks version 2.2.
Prepare the Environment
We’ll start by preparing the schema, creating a Kafka topic, and downloading security credentials that we’ll need in this tutorial.
Avro Schema
Kafka treats data as blobs of bytes. It is your responsibility to pick a data format per topic and use it consistently across applications interacting with the topic. You are free to choose any format you prefer such as JSON or Protobuf. However, Avro became the industry standard for data format to use with Kafka. Avro is an open source data serialization system that is used to exchange data between systems across programming languages.
Avro relies on schemas that are used when writing/reading data. To simplify the management of schemas, Confluent implemented a Schema Registry as a layer on top of Kafka. Hopsworks implements its own schema registry that is compatible with Confluent Schema Registry v5.3.1. Kafka clients can use the schema registry to validate and make sure that the correct data is written to or read from a kafka topic.
In this tutorial, we’ll use temperature sensors as an example. Each sensor will have a unique ID, produce a temperature as its value at a specific timestamp. We’ll create a generic sensor schema that can be used with sensors with similar pattern. The code blow list the schema used in this tutorial. For more details about declaring Avro schemas and supported data types, check the Avro schemas documentation.
To register the above schema in Hopsworks, open the schemas settings in the Kafka tab and select New Avro Schema
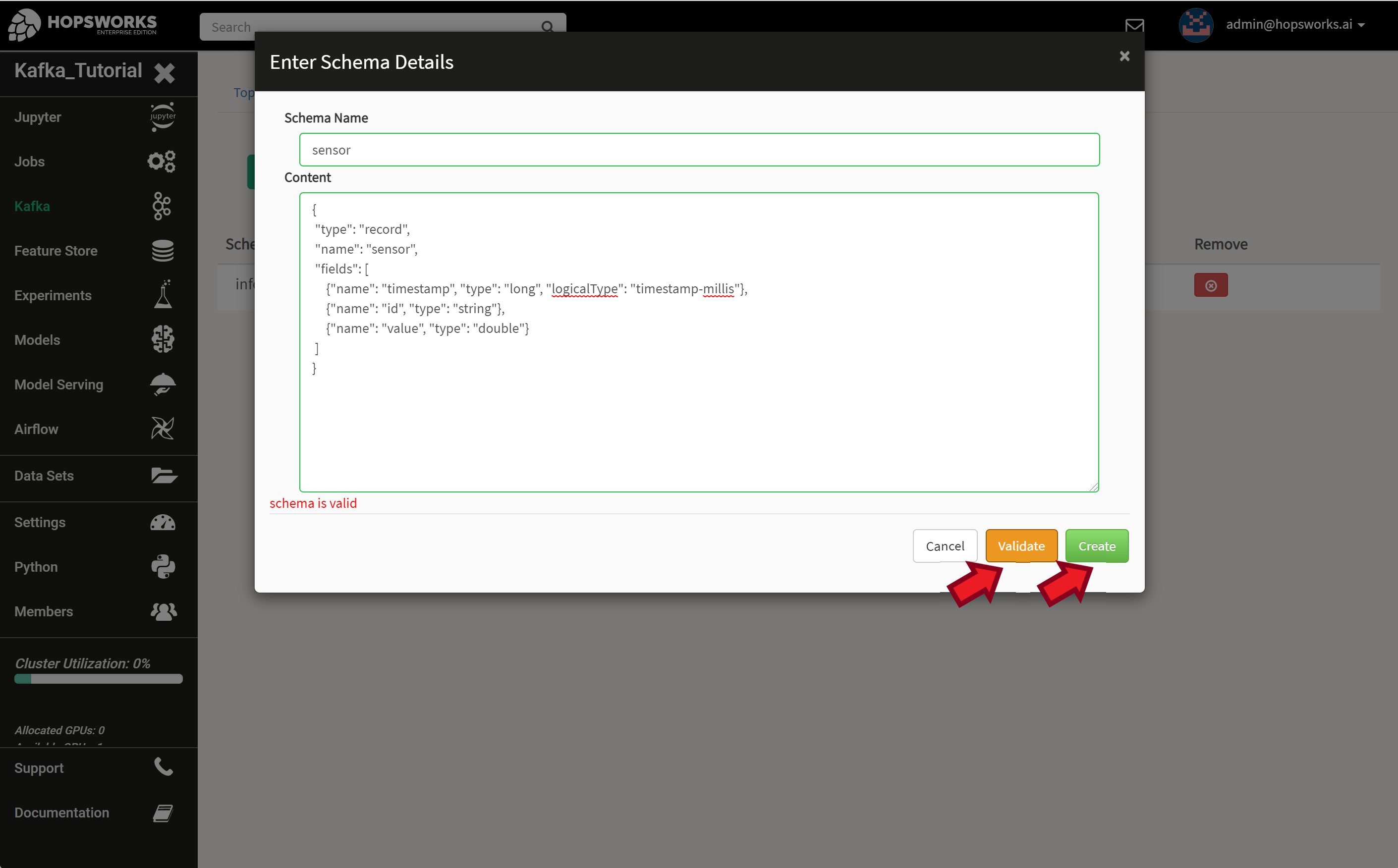
Then enter a Schema Name field for your schema and paste the schema itself in the content field. To check that the syntax of the schema is correct, press the Validate button. If everything is OK proceed by pressing the Create button.
Caution!
For the schema to work correctly with standard external clients, such as the Confluent Avro Producer/Consumer, the name given in the “Schema Name” field and in the schema declaration must be the same name. Furthermore, if you use a name space in the schema declaration, e.g., "namespace": "se.ri.kafka.tutorial", "name": "sensor", then the “Schema Name” field should contain the full name, i.e., se.ri.kafka.tutorial.sensor.
Kafka Topic
Topics are a way to organize related events. A topic is like a buffer between event producers and event consumers. Events are durably stored in a topic and are not deleted after consumption. Events can be read as many times as needed and you define for how long Kafka should retain your events.
For scalability, a topic is divided into a number of partitions that are distributed across servers (called Kafka Brokers). Events are distributed among partitions either uniformly or by event key. Using an event key is recommended to guarantee that events from the same entity, e.g., user or sensor, end up in the same partition and thus processed in the correct order of arrival.
Tip
The number of partitions determine the maximum parallelism for processing (consuming) events by a single application. You can have as many event producers per topic as you want. Also there can be as many applications processing (consuming) events from a topic as needed. But within a single application, also known as a consumer group, the maximum parallelism (number of consumers) is defined by the number of partitions in the topic. This restriction is to guarantee the ordered processing of events within a topic.
To create a new Kafka topic, open the topic settings in the Kafka tab and select New Topic.
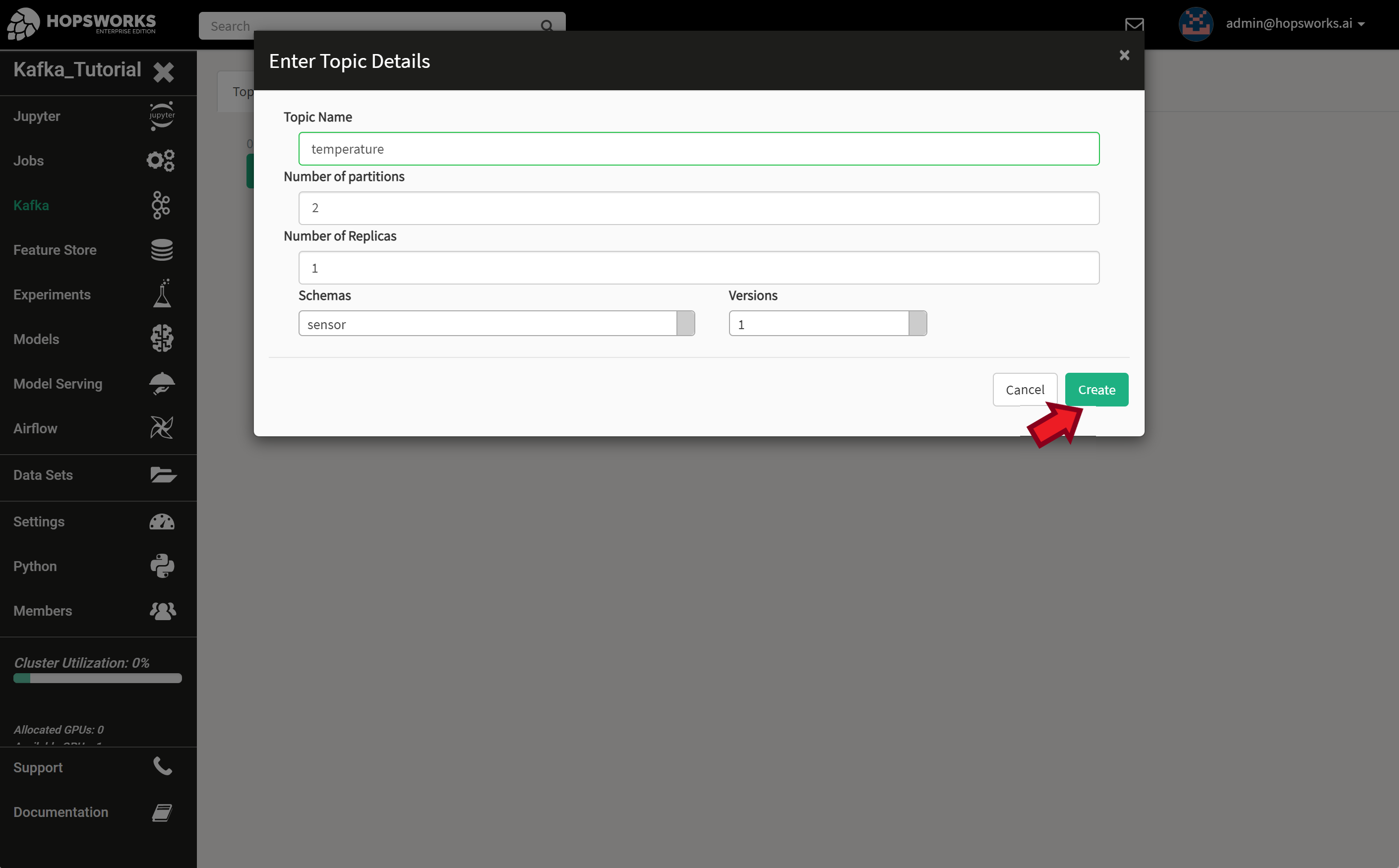
Give your topic a name. This will be used later in the code to identify the topic. Enter the desired number of partitions and replication degree. Select a schema and schema version to use with this topic. For this tutorial, use the values shown in the image below.
Note
For testing, it is OK to set the number of partitions and replicas to 1. In a production system, you should always set the number of replicas to larger that 1 (typically 3) to avoid data loss on server failures and also select appropriate number of partitions to achieve the desired performance based on the expected number and rate of events.
Security Certificates
Hopsworks provide a secure Kafka-as-a-Service. Connecting your Python Producers and Consumers from an external server to the one provided by Hopsworks requires exporting the project certificates. These are used by the clients to securely connect and authenticate against the Hopsworks Kafka cluster. The certificates are downloaded as a keystore and trustore. These are designed used by Java/Scala programs and needs to be converted to .pem format to be used by Python and other non Java programs.
To export your projects’ certificates, go to Project Settings in the Settings tab and click Export Certificates.
You will be asked to enter your login password before downloading.
After successfully entering your password, two certificate files will be downloaded, trustStore.jks and keyStore.jks. The certificate password will be displayed. It’s a long string that is similar to:
MQJNW833YNBR9C0OZYGBGAB09P2PP4H5EHIALGWIT98I2PNSPTIXFCEI72FT0VLE
Important
Store these two files in a safe place as they give remote access to your project and data. Same goes for the password. Copy and save your password in a safe location as we’ll need it later.
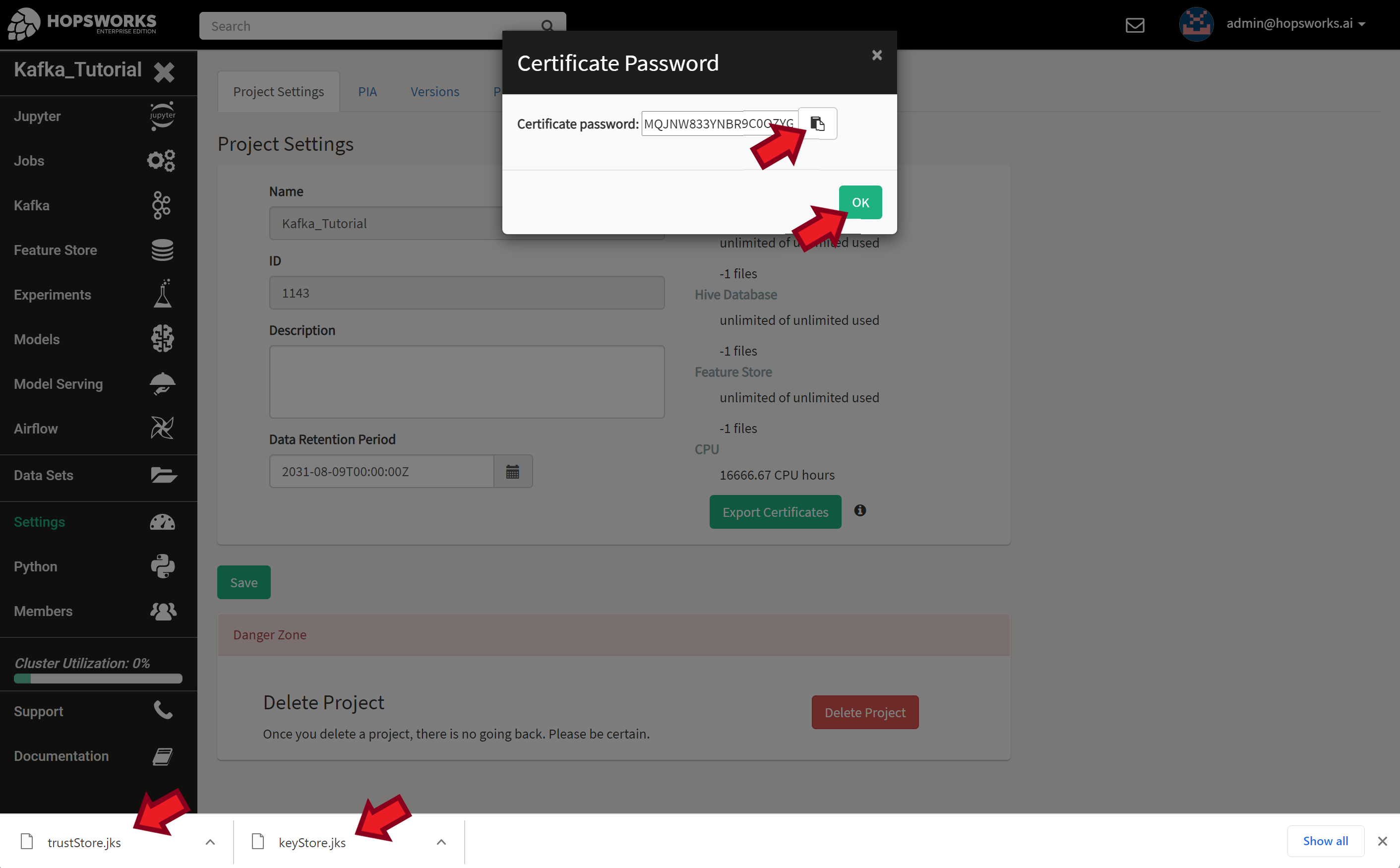
Next, we’ll convert the JKS keyStore into an intermediate PKCS#12 keyStore, then into PEM file. You will be asked to enter a new password for each of the generated certificates and also the original certificate password you got from the previous step.
We repeat the same steps for the trustStore.
Now you should have keyStore.pem and trustStore.pem that we’ll use in the rest of this tutorial. You can safely delete the intermediate .p12 files.
API Key
Hopsworks provides a rich REST API to interact with most of the available services. One of these services is the Schema Registry that we’ll be using in this tutorial. To access the REST API we’ll need an API Key.
To create a new API Key associated with your account, open your user account settings.
Select the API Keys tab. Give your key a name and select the services that the app using this key can access. Then click on Create API Key.
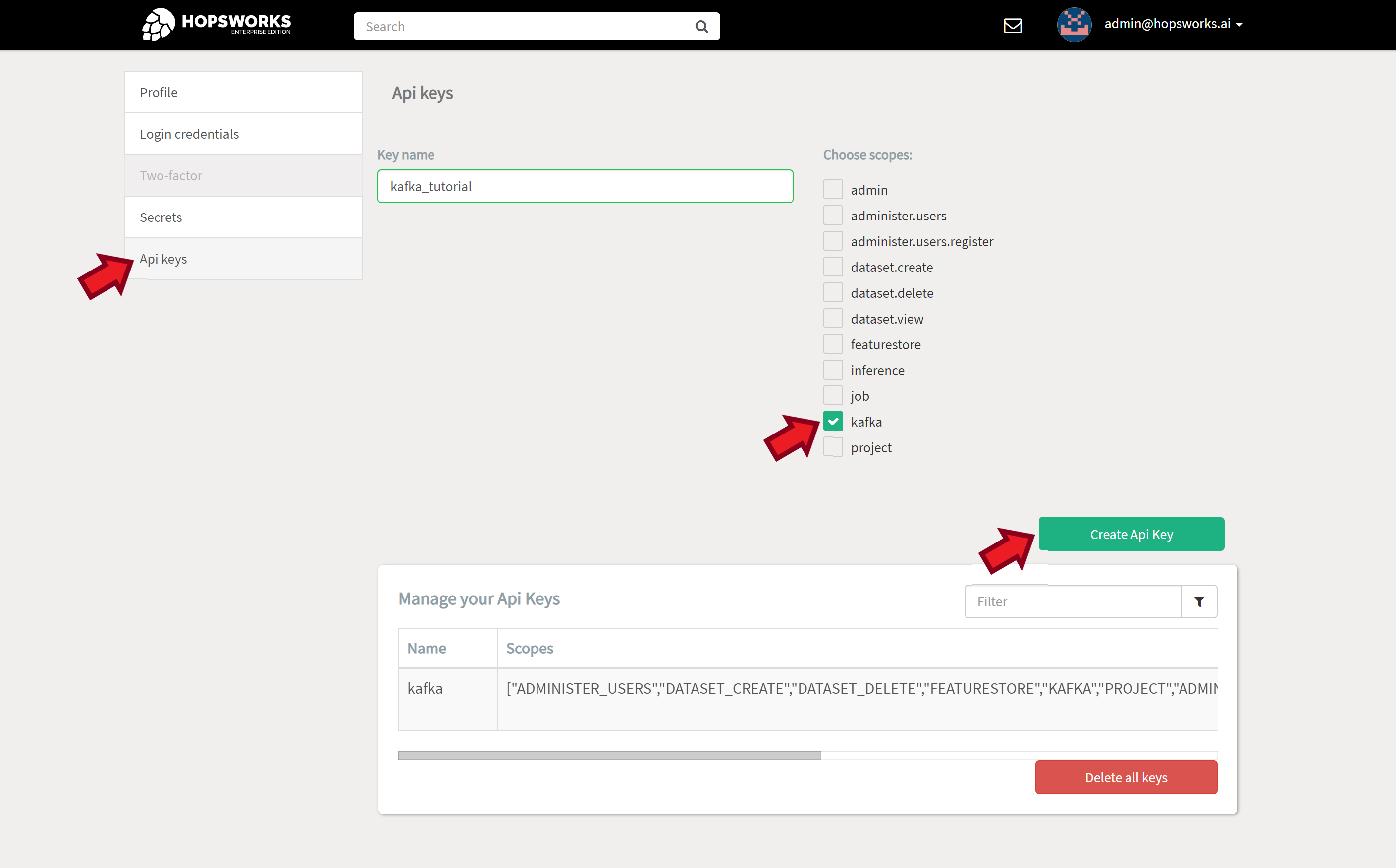
Copy and store your new key in a safe place as this is the only time it will be displayed. If you loose your API Key you’ll have to delete it and create a new one.
Your API Key will look something like this:
K97n09yskcBuuFyO.scfQegUMhXfHg7v3Tpk8t6HIPUlmIP463BPdbTSdSEKAfo5AB8SIwY8LGgB4924B
Important
Store your API Key in a text file (e.g., apiKeyFile) next to your certificates. We’ll use this file later to configure clients.
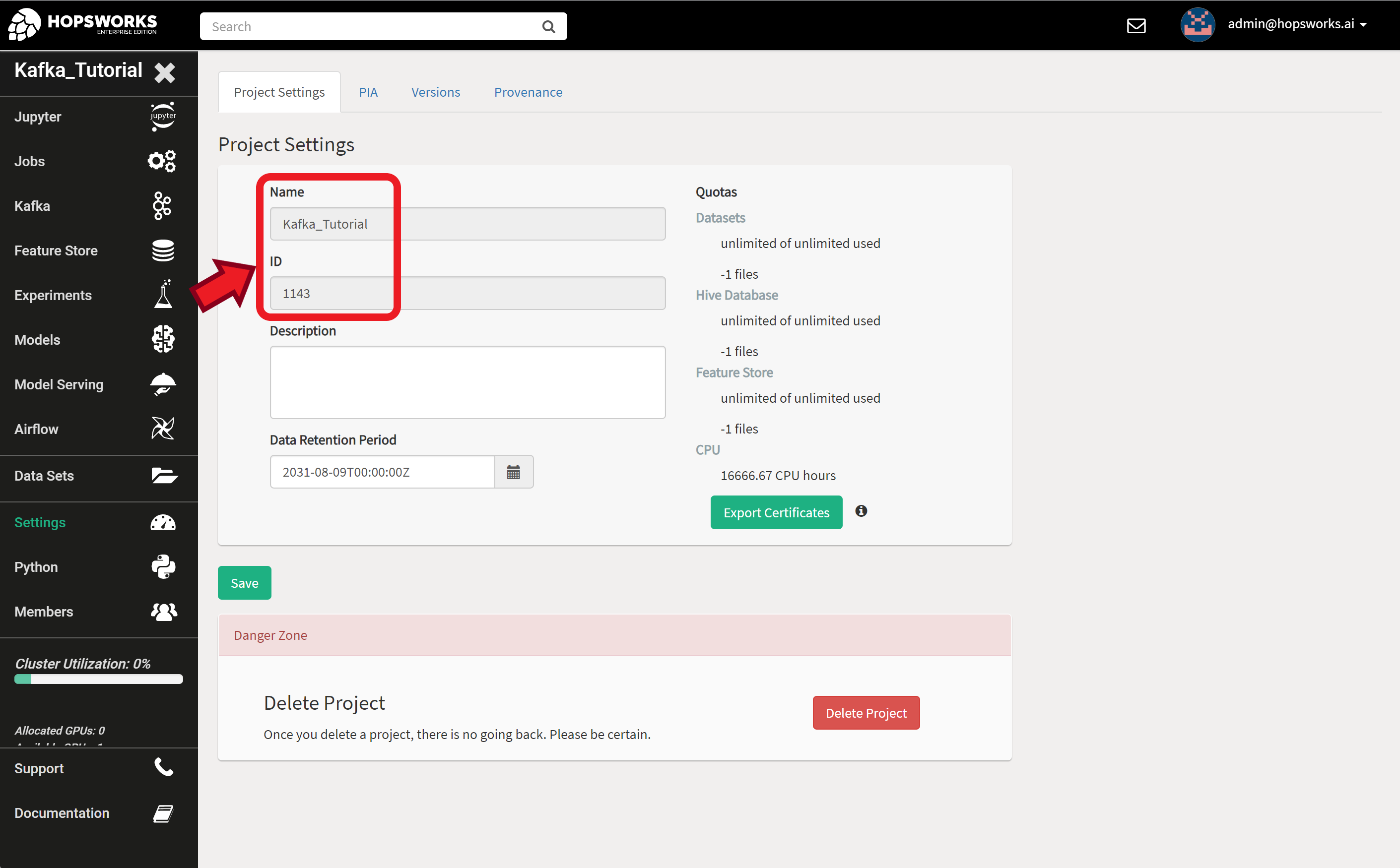
Project Name and ID
The final piece if information we need is the project name and ID. You will find this in your project settings tab.
Avro Client
Now we are ready for some coding. We’ll create a Kafka Producer and Consumer using the standard confluent-kafka library and connect it to a Hopsworks cluster. You can find the source code for all examples at Kafka Hopsworks Examples at GitHub.
You will need a working Python environment and the following packages:
For plotting you might need the following packages depending on your environment:
Configuration File
We’ll write down all the parameters we prepared in the previous section in a configuration file. This makes it easier to change and also to switch between multiple projects or deployments by switching configuration files.
Go through the parameters and change them accordingly to match your project settings. Then save it as config.toml
Sensor Data
We’ll need some data to test our example. For that we’ll generate a time series with trend, seasonality, and noise. The code can emulate multiple sensors. The generated data looks like the plot below.
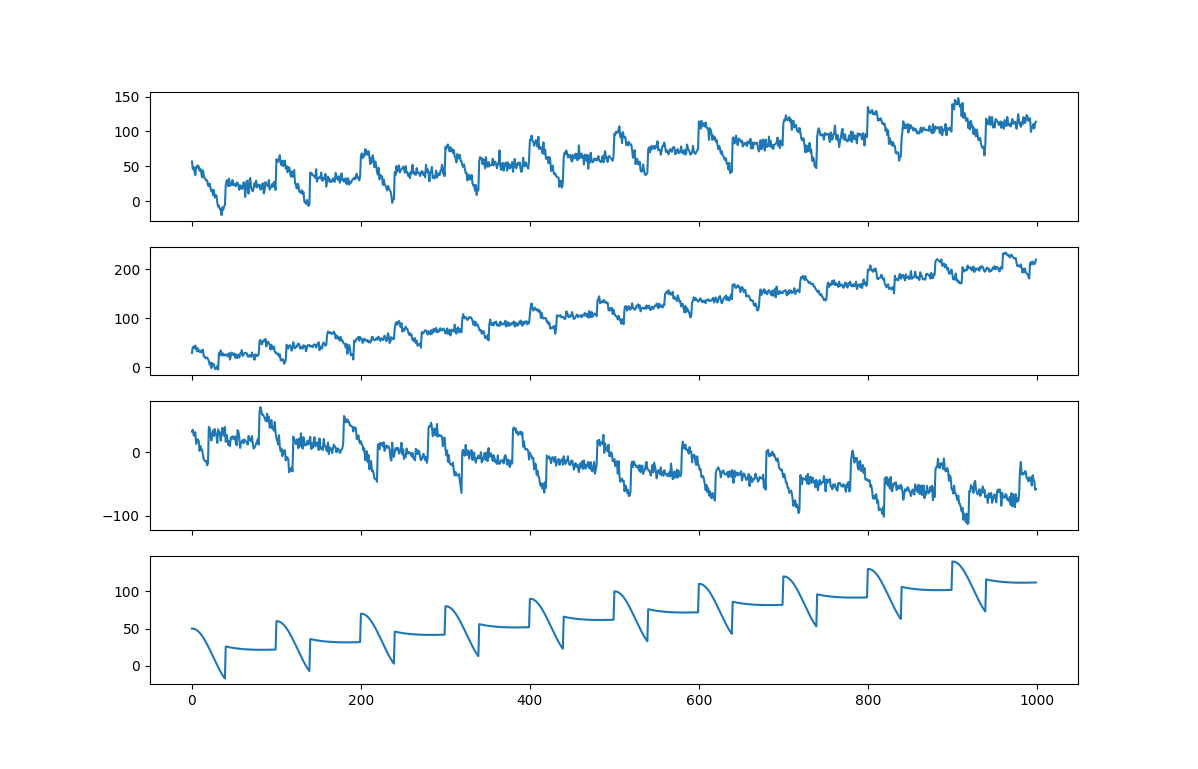
The code below for sensor.py generates the data. The code was inspired by this example. You can test it yourself by executing the file.
Avro Producer
With all preparation work out of the way, we are now ready to securely send sensor events into our HopsWorks Kafka topic. Below is the code for the avro_producer.py.
The code starts by defining an “Event“ class. This is the class for the objects we want to push into Kafka. You can change this class to match your application. The “event_to_dict“ is a helper function that returns a dictionary representation of an event object to be used by the Avro serializer. Note that the key names should match the field names defined in the schema and also the value types should match those in the schema.
The “main()“ function loads the configuration file and initializes the schema registry client, Avro serializer, and the producer. Then initializes a number of sensors to generate data and finally uses the producer to push the generated data into Kafka.
The program takes a number of optional command line arguments to control the execution. You can specify the location of the configuration file using the -c flag. You can use -e to control the number of events generated per sensor and -d for the delay between events per sensor. The -t flag is used to resume the generation of the time series from the specified time step. This is useful if you want to continue generating more events after the program finishes or stopped.
Warning
There is a bug in the HopsWorks REST API implementation for the schema registry that causes an HTTP error code 415 “Unsupported Media Type”.
The reason for this error is a mismatch of the content type sent between the client and the server. The Confluent schema registry client is sending the correct type which is ‘application/vnd.schemaregistry.v1+json’. While the Hopsworks REST API server is expecting content of type ‘application/json’. The bug is reported to the HopsWorks team and is expected to be fixed in upcoming releases after v2.2.
The easiest workaround is to change the Confluent schema registry client to send content type ‘application/json’. This should be OK if you are using Python virtualenv as this change will not affect other applications.
Edit the file schema_registry_client.py in your local python install directory and search for the line with ‘Content-Type’ (line 165 in confluent-kafka v1.7.0) and change it to: 'Content-Type': "application/json"}.
The location of the file depends on your Python installation. If you are using virtualenv it will look something like: ~/.virtualenvs/myvenv/lib/python3.8/site-packages/confluent_kafka/schema_registry/schema_registry_client.py
Now let's generate some events. Below is a sample execution of 5 events with 0.5 seconds delay:
Let’s generate some more events. Notice the last line in the execution above. It prints the time step that should be used to continue execution. To do that, we add -t 5 to the command:
Note
Remember that when we created the ‘temperature’ topic we set the number of partitions to two. In the output sample the partition number is shown in the square brackets after the topic name. For example ‘temperature [0]’. This means that the event was successfully sent to the temperature topic at partition 0.
Notice that events from the same sensor (e.g., sensor5) always ends up in the same partition (partition [1] in case of sensor5). This is enforced by Kafka to guarantee the ordered processing of events per event source. This is implemented using the key of the produced event which in our case is the sensor id. So pay attention to what you choose as the key depending on the application.
Avro Consumer
The Avro consumer code is similar to the producer code in previous section. It starts with the “Event“ class which is the same as the one in the producer code. The rest is similar but works in the other direction. So now we have a “dict_to_event“ helper function that will return an event object and in the “main()“ function we’ll initialize an Avro deserializer and a consumer. Finally the code loops to poll messages and plot the values.
Run avro_consumer.py with the command below. It will start receiving and plotting the 10 events we produced in the previous example. After that the program will wait for more events. Keep it running as we’ll be producing more events soon.
Note
The consumer received the 10 events we generated in the previous section because we set the auto.offset.reset property to 'earliest' in our configuration file. This causes a consumer group, when first created, to get all available events in the Kafka topic. Another option is 'latest' which will cause the consumer group to get only the current events ignoring old ones. Read more about consumer groups and offset management here.
Keep the avro_producer.py running and try generating 20 more events with the command below.
The producer will start producing more events and you will see the consumer receiving and plotting them. The output should be similar to the figure below.
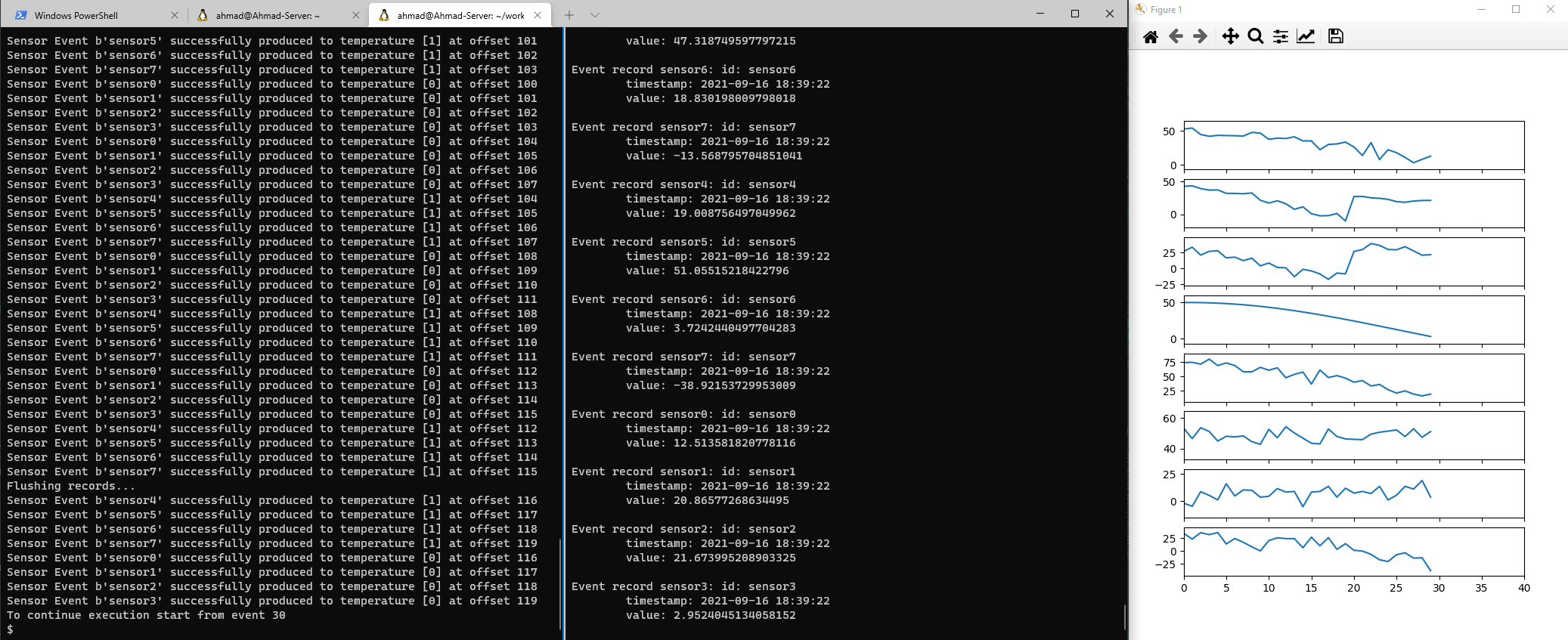
Now try creating another avro_consumer.py in another terminal leaving the previous one running.
Then produce 20 more events:
Notice that now the produced events will be split between the two consumers, or to be more precise, the partitions will be split among the available consumers. Since we created two partitions, we can have a maximum of two consumers. The output should look similar to the image below.
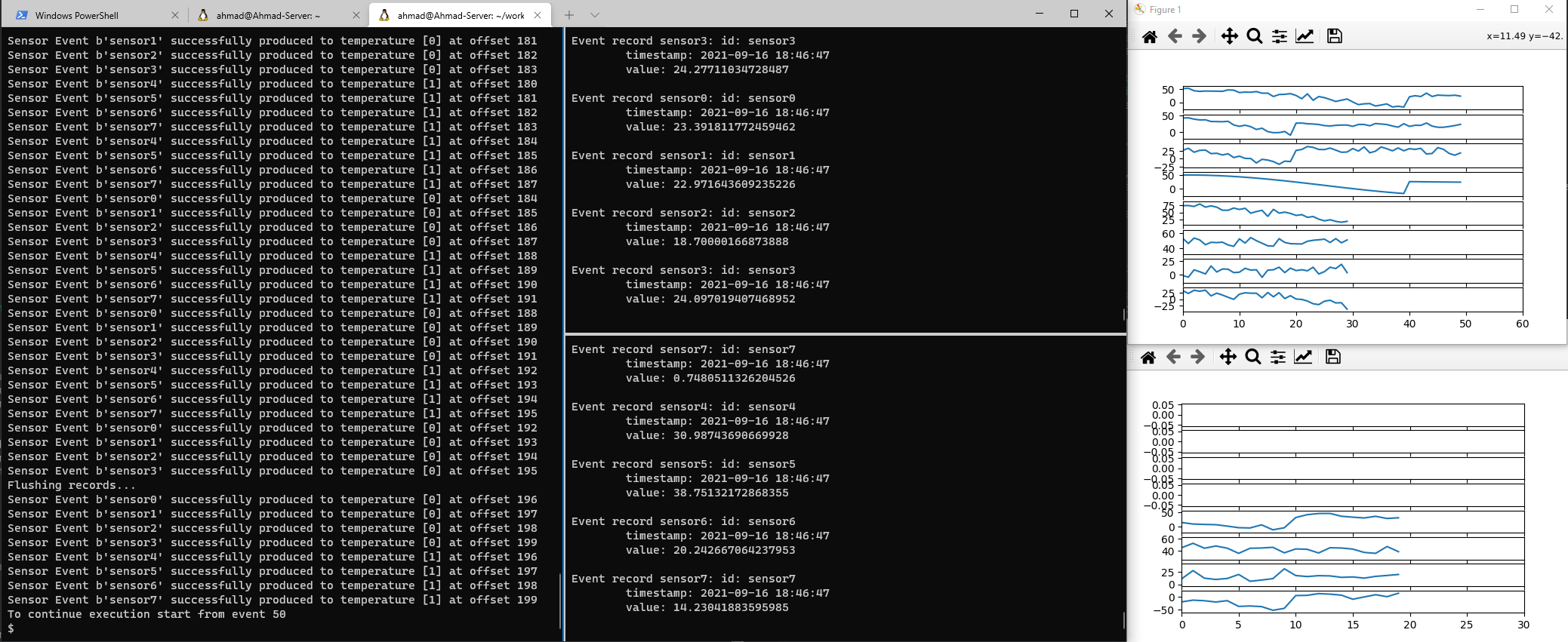
Note
Kafka remembers the events consumed by a consumer group. So if a consumer is interrupted and then restarted, it will continue from where it stopped. This is achieved through the consumer commit the offsets corresponding to the messages it has read. This can be configured to provide different delivery guarantees. The default is auto-commit that gives you at least once delivery guarantee. You can read more about this topic here.
Schema Registry Clients (Optional)
In some cases you might need to programmatically access the schema registry and retrieve the schema associated with a topic or by schema name. In this section we’ll show three different ways to do this. The source code for the examples is available at schema_examples.py.
To run this example you will need hops-util-py which is a helper library for HopsWorks that hides some of the configurations and initializations needed to access HopsWorks services. Install it with the following command.
The code starts by importing required libraries and loading the configuration file.
The first example uses the HopsWorks REST API directly to query the schema registry. You need to construct a url for your query following the API documentation. In our case that is getTopicSubject. Then use a library, such as requests to send your query and retrieve the response. Note that you need to add your API Key to the request header.
The second example uses the handy hops-util-py library. All you need is to connect to your project using the project name, url, and API Key. Then use kafka.get_schema('topic_name')) to get the schema.
The third example uses the Confluent Schema Registry client. You will need to construct the url for the schema registry of your project then use it to initialize the schema registry client. You will also need to add the API Key to the header.
Now you can use the client to query the schema registry. In this example we use sc.get_latest_version('schema_name') to retrieve the schema.
Simple Producer/Consumer (Optional)
For completeness we include the code for simple_producer.py and simple_consumer.py. By simple we mean that it doesn’t use Avro schemas and doesn’t validates schema. Kafka only sees blobs of bytes. It is up to you to keep track of what is stored in the topic and how to interpret the value.
Warning
Before running the simple_producer.py example make sure to create a new topic to avoid conflicts with the Avro examples. Also make a copy of your config.toml file and change the topic to match your new topic and use a different group_id than the one used in the Avro examples. When running the example use the -c flag to point to your new configuration file.
Source Code
All source code is available at Kafka HopsWorks Examples at GitHub.