Federated Data with the Hopsworks Feature Query Service
Python clients can read from Snowflake, BigQuery, Hopsworks, and more
A tutorial of the Hopsworks Feature Query Service which efficiently queries and joins features from multiple platforms such as Snowflake, BigQuery and Hopsworks without data any duplication.

Introduction
It is common for organizations to have their features spread across multiple platforms and cloud providers due to the fact that different teams with different needs develop solutions that suit them best. Having your features spread across multiple platforms usually means that you have to ingest and duplicate all these features into a feature store in order to be able to share and reuse them effectively. In Hopsworks, we solve this problem by introducing the Hopsworks Feature Query Service, powered by ArrowFlight and DuckDB, which efficiently queries and joins features from multiple platforms such as Snowflake, BigQuery and Hopsworks without any data duplication.
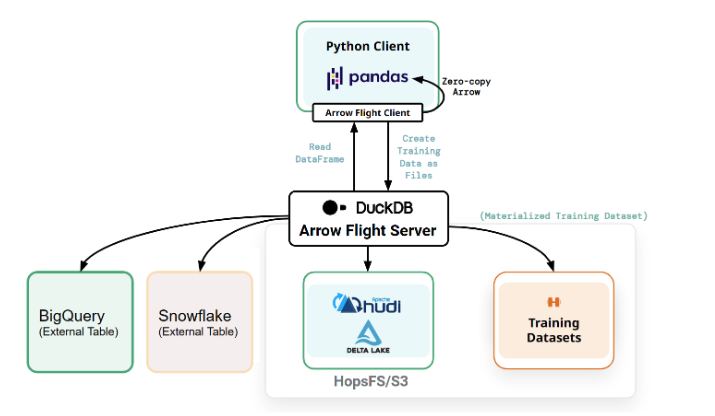
Figure 1. Federated Queries with Hopsworks Feature Query Service
If you are interested in how the Hopsworks Feature Query Service works, you can find the details in our earlier blog post: Faster reading from the Lakehouse to Python with DuckDB/ArrowFlight.
Prerequisites
To follow this tutorial you can sign up for the Hopsworks Free Tier or use your own Hopsworks installation. You also need access to Snowflake and BigQuery, which offer free trials: Snowflake Free Trial, Google Cloud Free Tier.
If you choose to use your own Hopsworks, you should have an instance of Hopsworks version 3.5 or above and be the Data Owner/Author of a project. Furthermore, to use the Hopsworks Feature Query Service, the user has to configure the Hopsworks cluster to enable it. This can only be done during cluster creation.
The tutorial
The aim of this tutorial is to create a unified view of features regarding the 100 most popular GitHub projects joining public datasets on Snowflake (GitHub Archive). BigQuery (deps.dev) and Hopsworks. We will create feature groups for each of these sources and then combine them in a unified view exposing all features together regardless of their source. We then use the view to create training data for a model predicting the code coverage of Github projects.
Setting up the Snowflake connection
Hopsworks manages the connection to Snowflake through storage connectors. Therefore, the following steps show you how to retrieve the connection information from Snowflake and provide it to your Hopsworks project.
Gain access to the GitHub Archive dataset on Snowflake
Start by logging in to your Snowflake account. If you don’t have a Snowflake account yet then you can register for a free trial on their homepage.
Go to the GitHub Archive dataset and add it to your account:
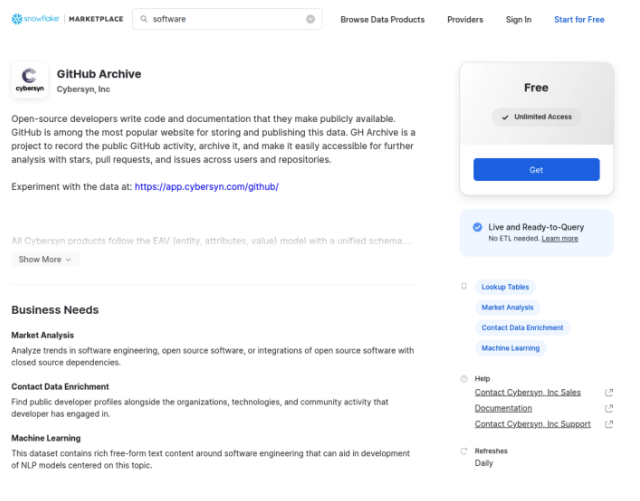
Get connection information for Snowflake
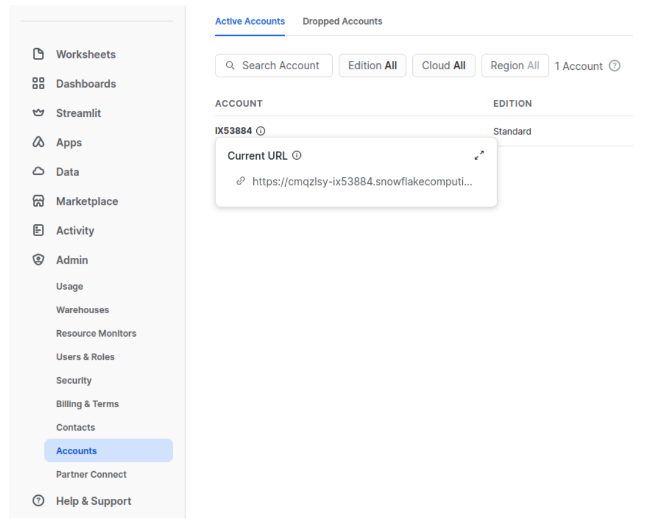
In the Snowflake web user interface, go to Admin -> Accounts and hover your mouse pointer to the right of the account id until the Current URL appears. This is your connection URL:
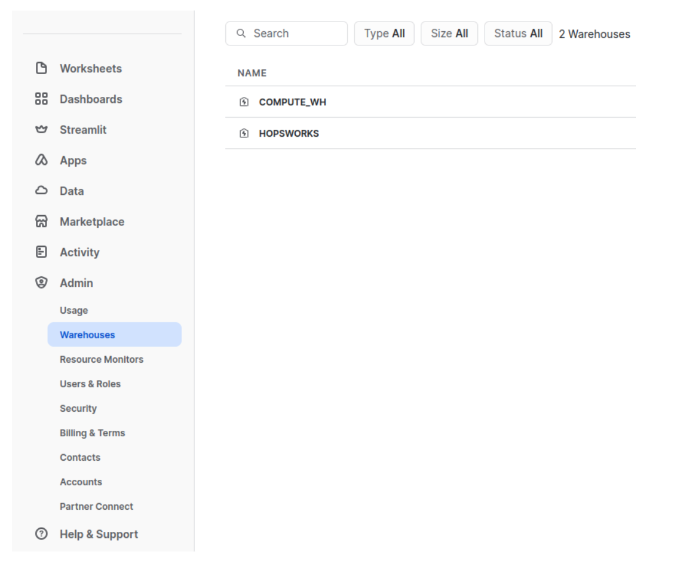
In the Snowflake web user interface, go to Admin -> Warehouses and take note of the name of the warehouse you want to use:
Define the connection to Snowflake using a Hopsworks storage connector
Next, in Hopsworks select a project where you want to connect to Snowflake and create a new storage connector for Snowflake. Enter the following details and save the connector:
- Name: Snowflake
- Protocol: Snowflake
- Connection URL: The connection URL you looked up earlier
- User: Your Snowflake user name
- Password: Your Snowflake user password
- Warehouse: The name of the warehouse you looked up earlier
- Database : GITHUB_ARCHIVE
- Schema: CYBERSYN
After entering the connection information the connector should look something like this:
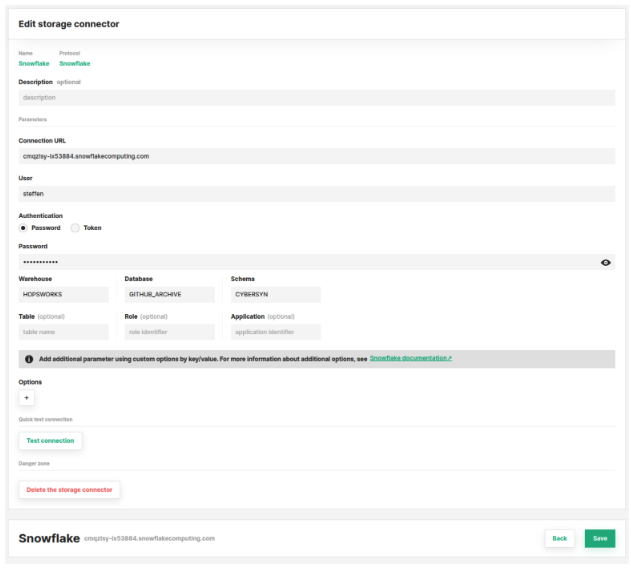
Setting up the BigQuery connection
Hopsworks manages the connection to BigQuery through storage connectors. Therefore, the following steps show you how to retrieve the connection information from Google Cloud and provide it to your Hopsworks project.
Gain access to the deps.dev dataset on BigQuery
Start by logging in to your Google Cloud account. If you don’t have a Google Cloud account yet then you can sign up for the Google Cloud Free Tier.
We will be using the public deps.dev dataset which is available to all BigQuery users:
Get connection information for BigQuery
In the Google Cloud web interface, open the project selector in the top bar and take note of the ID of the project you want to use:
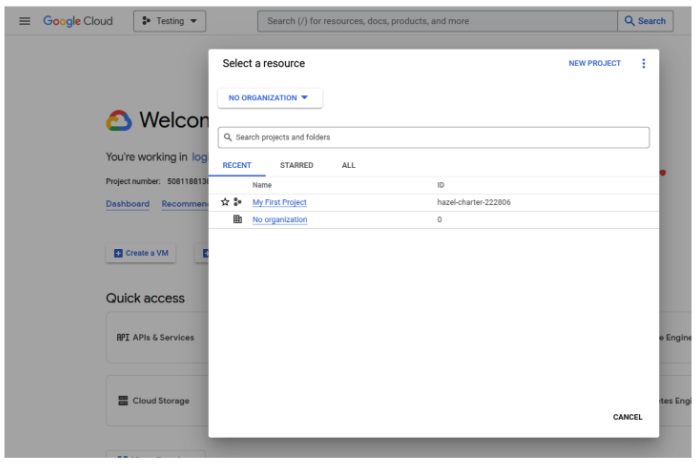
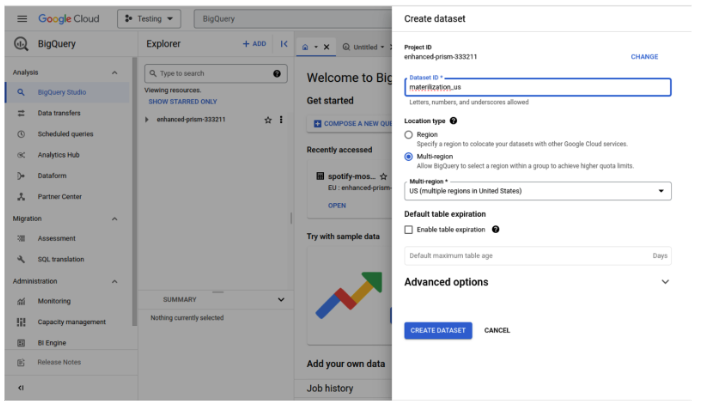
In the Google Cloud web interface, go to BigQuery -> BigQuery Studio and select Create dataset using the three dots on the project you want to use. Fill in the dataset ID materialization_us and select location type Multi-region, US. Note that you have to use the multi-region US as the dataset we are using is located there.
In the Google Cloud web interface, go to IAM -> Service accounts, select the service account you want to use and use the three dots to open Managed keys. Create and download a JSON key file for your service account:
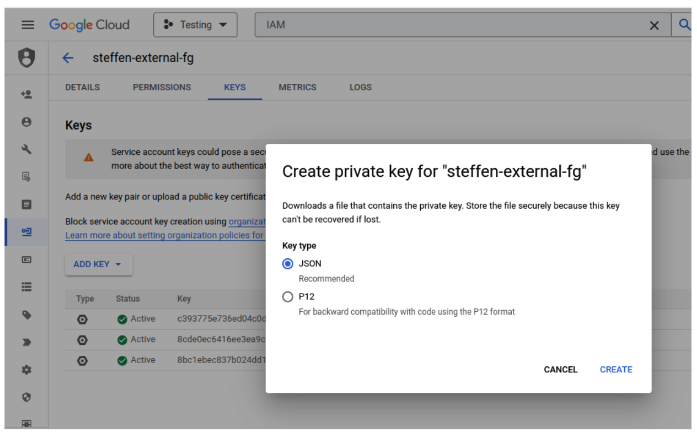
Note that the service account you use needs permissions to execute BigQuery jobs as well as permissions to write to the materialization_us dataset created earlier. This can be achieved by assigning the roles BigQuery Data Owner, BigQuery Job User, BigQuery Read Session User and Service Usage Consumer to your service account. Alternatively, you may define more restrictive permissions manually.
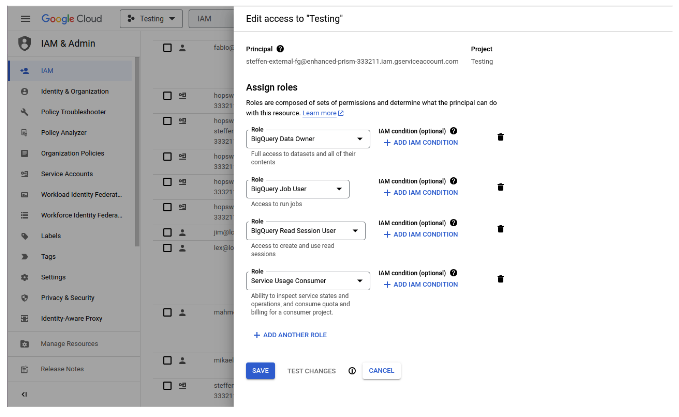
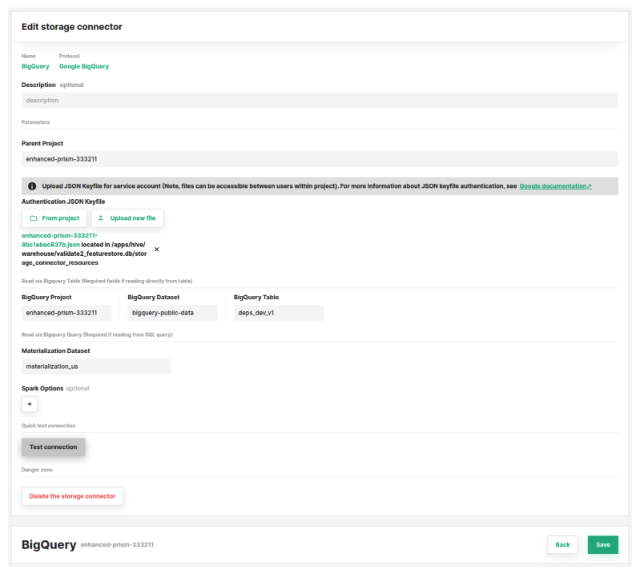
Define the connection to BigQuery using a Hopsworks storage connector
Next, in Hopsworks select a project where you want to connect to BigQuery and create a new storage connector for BigQuery. Enter the following details and save the connector:
- Name: BigQuery
- Protocol: Google BigQuery
- Parent Project: The project ID you looked up earlier
- Authentication JSON Keyfile: Upload the JSON key file you created earlier
- BigQuery Project: The project ID you looked up earlier
- BigQuery Dataset: bigquery-public-data
- BigQuery Table: deps_dev_v1
- Materialization Dataset: The ID of the materialization dataset you created earlier, e.g. materialization_us
After entering the connection information the connector should look something like this:
Create a Feature View joining a Feature Group with External Feature Groups in Snowflake and BigQuery
We will now use a Python notebook on JupyterLab to create and query a federated feature view that extracts the 100 most popular Github repositories from the Snowflake dataset and amends them with features from BigQuery and Hopsworks.
Prepare Jupyter
To be able to run the Jupyter notebook, we need to install Jupyter and the Hopsworks dependencies before starting Jupyter:
Connect to Hopsworks
In Jupyter, create a new Python 3 notebook and copy the following code into the first cell and execute it to connect to Hopsworks and retrieve the storage connectors:
Create an External Feature Group on Snowflake
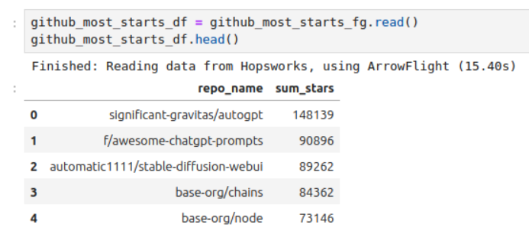
We now create an external feature group querying the GitHub Archive dataset on Snowflake to return the 100 repositories that got the most stars during the 365 days before Nov 11, 2023.
After creating the external feature group on Snowflake, we are now able to query it in our notebook utilizing the Hopsworks Feature Query Service:
The result will be returned in a matter of seconds:
Create an External Feature Group on BigQuery
We now create an external feature group on BigQuery containing information about the licenses, number of forks and open issues from the deps.dev dataset. To limit the cost, we limit the content to the 100 repositories from the github_most_starts feature group:
After creating the external feature group on BigQuery, we can now query it in our notebook utilizing the Hopsworks Feature Query Service:
After a few seconds, you will get the result:
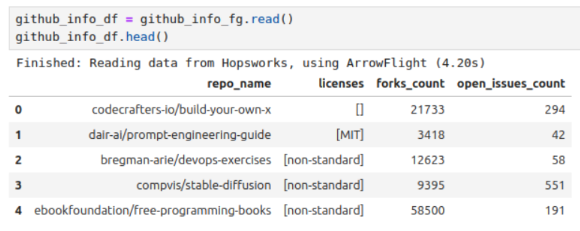
Create a Feature Group on Hopsworks
To show that the data from the datasets on Snowflake and BigQuery can be queried together with data on Hopsworks, we now make up a dataset for the code coverage of repositories on GitHub and put it into a feature group on Hopsworks:
After creating the feature group, we can look at it:
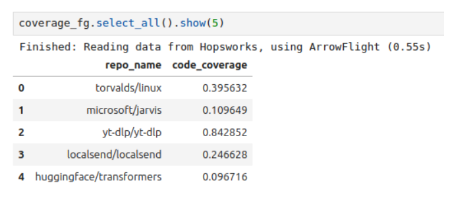
Create a Feature View joining all Feature Groups together
We now join the two external feature groups on Snowflake and BigQuery with the feature group in Hopsworks into a single feature view and mark the feature code_coverage as our label to be able to create training data in the next step:
We can query the feature view in the same way we query any other feature view, regardless of the data being spread across Snowflake, BigQuery and Hopsworks. The data will be queried directly from its source and joined using the Hopsworks Feature Query Service before being returned to Python:
The result is returned in a matter of seconds, even though we queried three different platforms:
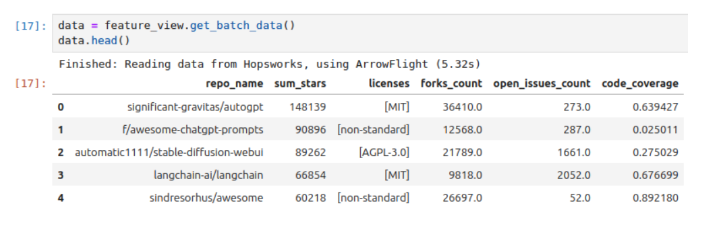
Create the training data from the Feature View
Finally, we can use the feature view to create training data that could be used to train a model predicting the code coverage of the GitHub repositories:
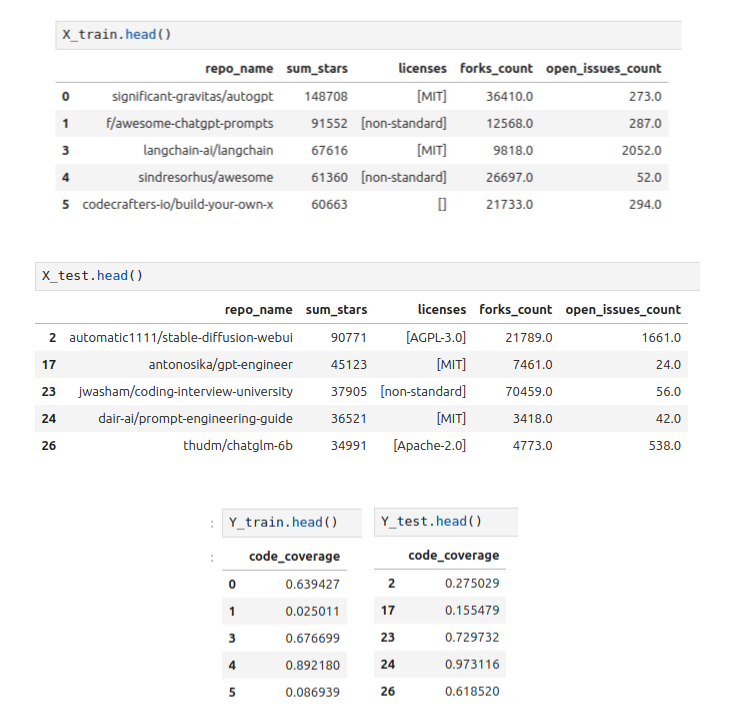
Summary
In this blog post, we have shown how to use the Hopsworks Feature Query Service by joining features across Snowflake, BigQuery and Hopsworks with low latency and no data duplication. This enables users to have a unified interface for their features even though they are originally created across multiple platforms that suit the producing team best.
The full source code for this blog post is available on GitHub. You will need a Hopsworks 3.7+ cluster, access to Snowflake, and BigQuery to complete this tutorial.