Feature Data
What is Feature Data?
Feature data, often referred to simply as features, is simply the data that is passed as input to machine learning (ML) models. You use feature data both when training a model and when making predictions with a model (inference) - in both cases the input to the model is feature data. Feature data could be diverse, ranging from numerical attributes like age and price to categorical variables such as hair color or genre preference. Feature data act as the inputs to algorithms, providing crucial information for training ML models. It serves as the cornerstone for building robust models capable of making accurate predictions and classifications across various domains.
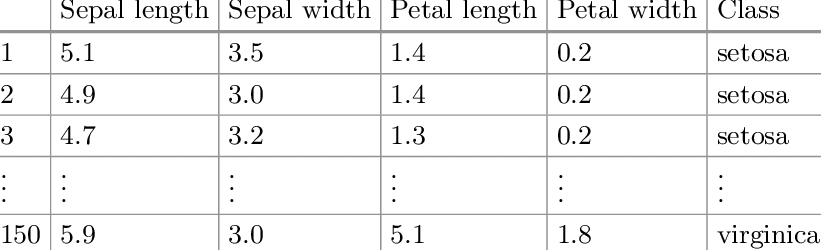
Example of feature data in the Iris flower data set - the features are the sepal length, sepal width, petal length, and petal width. The other columns are not features - the leftmost column is an ID for each row (an index in Pandas) and the rightmost column is the label.

In tabular data, feature data is the sequence of columns that are used as input to the model. Feature data can be encoded or, in the above table, unencoded. Depending on the model that will use the feature data, it may need to be encoded into a numerical format and/or scaled/normalized.
Features Types
In the table above, each feature contains either quantitative or qualitative information. Quantitative data is numerical. For example, the amount of rainfall or the temperature. Qualitative data is discrete, with a finite number of well-known values, like purpose in the above table.
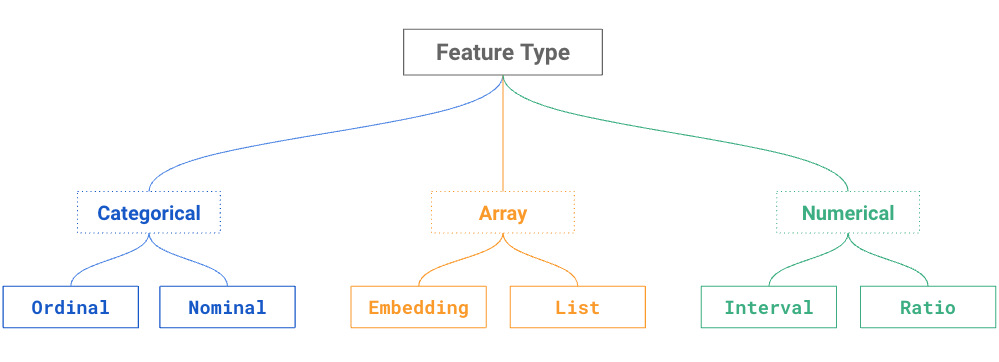
A taxonomy of feature types is shown in the figure below, where a feature can be a discrete variable (categorical), a continuous variable (numerical), or an array (many values). Just like a data type, each feature type has a set of valid transformations. For example, you can normalize a numerical variable (but not a categorical variable), and you can one-hot encode a categorical variable (but not a numerical variable). For arrays, you can return the maximum, minimum, or average value from a list of values (assuming those values are numerical). The feature type helps you understand what aggregations and transformations you can apply to a variable.
Engineering Feature Data
The essence of feature data lies in its ability to encapsulate relevant information about the problem at hand, enabling algorithms to learn patterns and make informed decisions. However, not all data can be directly used by ML models. Real-world raw data can be from different data sources, unstructured and contain redundant information. Including irrelevant features can confuse the model and hinder its ability to identify the true patterns. Feature engineering helps bridge this gap by transforming raw data into meaningful features the model can understand. It allows us to select the most informative and discriminating features, focusing the model's learning process on what truly matters.
Feature engineering emerges as a crucial process in the ML pipeline, where raw data is transformed to extract meaningful features. This process involves tasks like data cleaning, feature selection, feature extraction, feature scaling, feature encoding, and so on.
Selection of Feature Data
Not all features are equally important. Depending on specific tasks, some features may carry more predictive power than others. Using irrelevant features can confuse the model and hinder its ability to learn. Feature selection identifies the most relevant features from the pool of available data, eliminating noise and redundancy. It can help ML models improve performance from the following perspectives:
-
Curse of dimensionality: In high-dimensional spaces, the number of features can sometimes outnumber the number of data points or samples. This imbalance often leads to overfitting, where models learn noise in the data rather than true patterns. Feature selection mitigates this risk by focusing on only the most informative features.
-
Improved generalization: Models trained on only the relevant features are more likely to generalize well to unseen data. By selecting informative features, feature selection enhances the model's ability to capture underlying true patterns and make accurate predictions on new samples.
-
Computational efficiency: Including irrelevant or redundant features increases the complexity of the model and the computational cost of model training and inference. By excluding unnecessary features, execution times can be faster and the cost of computational resources can be reduced.
Extraction of Feature Data
Feature extraction is to derive new features from the existing ones to capture complex relationships or reduce dimensionality. Feature extraction can be thought of as a distillation process where the most salient aspects of the data are extracted and distilled into a more manageable form. This distilled representation retains the key information required for the intended task while discarding less relevant details. The following techniques help distill essential information.
-
Principal Component Analysis (PCA): PCA is a popular technique for dimensionality reduction that identifies principal components along which the data exhibits the most variation. By retaining a subset of these components, PCA effectively compresses the data while preserving its variance.
-
Statistical methods: Techniques like calculating means, medians, and variances can extract features that summarize the central tendency or variability within the data.
-
Autoencoders: Autoencoders are neural network architectures used for unsupervised feature learning. They learn to encode the input data into a lower-dimensional representation (encoding) and then decode it back to the original input space. Autoencoders can capture complex relationships in the data and are capable of nonlinear feature extraction.
Scaling of Feature Data
Feature scaling, or data normalization, involves transforming the values of features within a dataset to a common range. This is particularly important when dealing with datasets containing features that have different units or varying ranges. For example, a dataset with features like "income" (in dollars) and "age" (in years). The raw values would have vastly different scales, with income values potentially reaching thousands or millions, while age often stays below 100.
Ensuring uniformity in feature magnitudes can prevent certain features from dominating others during model training. On the other hand, it can improve the gradient descent convergence of ML algorithms during gradient descent optimization, leading to smoother convergence towards the optimal solution. There are several popular techniques for feature scaling:
-
Min-max scaling (normalization): This technique scales each feature to a specific range, typically between 0 and 1 (or -1 and 1). It preserves the relative relationships between values in a feature but can be sensitive to outliers. It is suitable if the distribution of your data is unknown.
-
Standardization: This technique transforms features by subtracting the mean value from each data point and then dividing by the standard deviation. It results in features with a mean of 0 and a standard deviation of 1. This method is robust to outliers. It is suitable if your data has a Gaussian distribution and you want to emphasize features with higher standard deviations.
Encoding of Feature Data
ML algorithms typically work best with numerical data. Feature encoding transforms non-numerical variables (e.g., categorical data, text data) into numerical representations to feed into ML models. There are several ways to encode categorical features:
-
Label encoding: This method assigns a unique integer value to each category. It's simple and efficient but may lead ML models to misunderstand that the numerical orders are meaningful, for example, 3 is more important than 1. This encoding method is typically used for simple categorical data with few categories.
-
One-Hot encoding: This technique creates a new binary feature for each category. Each new feature indicates the presence (value of 1) or absence (value of 0) of that category. This method avoids the ordering issue but can lead to a significant increase in feature dimensionality (number of features) for datasets with many categories.
-
Word embedding: This is particularly used in large language models to represent words or phrases into vector representations while capturing semantic relationships and contextual information. Popular word embedding techniques include Word2Vec, GloVe, and FastText.
Storage of Feature Data
Feature data is often managed by a feature store that acts as a centralized repository for feature data. It serves as the backbone for feature engineering pipelines, facilitating the creation, transformation, and extraction of features from raw data sources. By providing a unified location for storing and managing features, it streamlines the feature engineering process, ensuring consistency and reusability across different ML projects and teams.
In dynamic environments where data can change frequently, a feature store becomes even more crucial as it provides a centralized and up-to-date repository for managing evolving feature data. This ensures that ML models can adapt to changing data patterns and maintain accuracy over time. Feature stores also incorporate versioning capabilities to track changes made to feature data over time, enabling reproducibility and auditability in model development.
Summary
Feature data consists of numerical, categorical, or textual attributes that encode valuable information, forming the foundation for constructing ML models. By effective selection, extraction, and encoding of features, raw data becomes meaningful representations, which is paramount for enhancing model accuracy, generalization, and efficiency, ultimately enabling intelligent systems to make informed decisions across various domains.