Training Pipeline
What is a Training Pipeline?
A training pipeline is a series of steps or processes that takes input features and labels (for supervised ML algorithms), and produces a model as output. A training pipeline typically reads training data from a feature store, performs model-dependent transformations, trains the model, and evaluates the model before the model is saved to a model registry. If model evaluation is complex, it can also be performed after the model has been saved in a model registry.
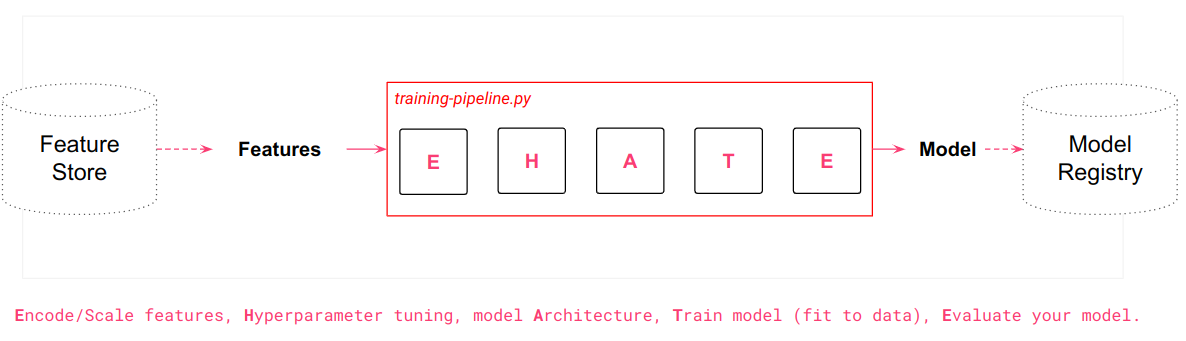
Some of the steps involved in training a model include the:
- selection of the features and the range of data to be used to train the model,
- splitting the training data into train/test/validation sets,
- encoding/scaling feature data before it is fed into the model for training,
- selection of a model architecture (e.g., tree-based, feedforward DNN, transformer)
- identification of good hyperparameters for the combination of prediction problem, training data, and model architecture,
- fitting the training data to the model (i.e., model training),
- model evaluation - validation/testing of the model's performance and checks for any model bias,
- registration of the trained model with a model registry.
Using a feature store in the training pipeline helps to achieve consistency across different training runs and ensures that the features used for training are of high quality and reproducible.