Online Inference Pipeline
What is an online inference pipeline?
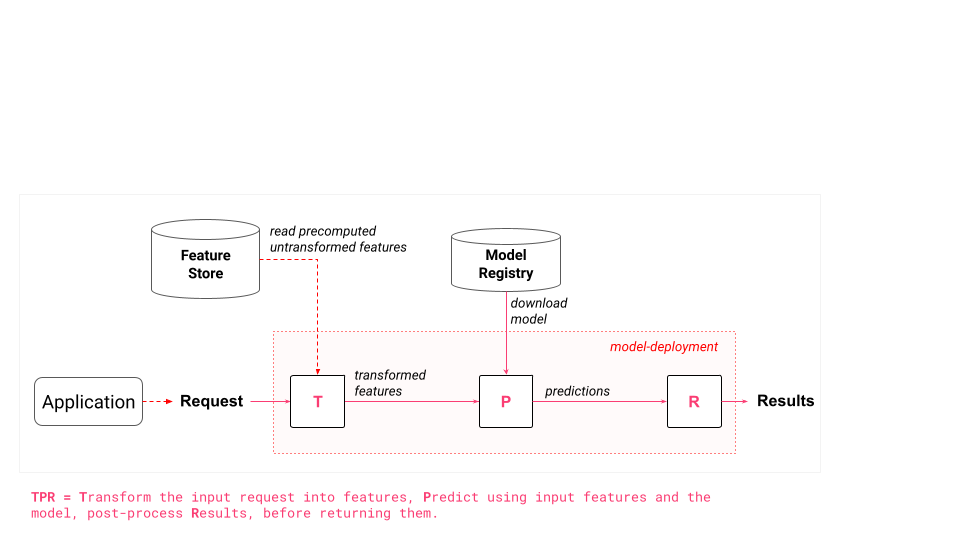
An online inference pipeline is a program that runs in a model deployment and returns predictions to a client using a model, downloaded and cached from a model registry, and features that are either on-demand or precomputed and retrieved from the feature store.
What are the key steps in an online inference pipeline?
An online application sends a prediction request to the model deployment that contains an inference pipeline that processes the input request, computes any on-demand features, retrieves any precomputed features from a feature store, applies any model-dependent transformations to the on-demand and precomputed features and builds a feature vector from them, before making a prediction on the model with that feature vector, and finally post-processes the prediction before it sends the results back to the client application.