PagedAttention
What is PagedAttention?
As large language models (LLMs) have advanced, many industries have been developing and serving systems with LLMs for diverse purposes. Models like GPT-4, Claude, Gemini, and many others have demonstrated impressive abilities to understand, generate, and reason about human language. However, when serving the LLMs to a greater audience, comes with significant memory and computational requirements.
Systems often struggle with high throughput serving due to inefficient memory usage. One key area of focus has been on the models' key-value (KV) caches - the large memory stores that hold the contextual information the models use during inference. PagedAttention is an innovative technique, proposed by Kwon et al., in their paper “Efficient Memory Management for Large Language Model Serving with PagedAttention”, that aims to dramatically reduce the memory footprint of LLM KV caches so to help make LLMs more memory-efficient and accessible.
Why is there a Need for PagedAttention?
LLMs like GPT-4 can have trillions of parameters, making them extremely powerful but also incredibly memory-hungry when inferencing during serving. The main bottleneck of memory is due to the KV cache.
KV cache
During the decoding process of transformer-based LLMs, as each input token is processed, the model generates corresponding attention key and value tensors. These key and value tensors encode important contextual information about the current input and its relationship to the broader context. Rather than recomputing these attention-related tensors from scratch for each step of the decoding process, the model stores them in GPU memory. This stored collection of key and value tensors is commonly referred to as KV cache.
By maintaining the KV cache, LLMs can retrieve and reuse the pre-computed contextual information when generating the next output token during inference. The cache acts as a sort of "memory" for the model to draw upon.
The challenge from the KV cache
However, the size of the KV cache can quickly become a bottleneck. For a 13B-parameter LLM, the KV cache can be 40 gigabytes in size (as illustrated in the paper). The size of the KV cache is also dynamic and unpredictable as it depends on the length of the input sequence.
Therefore, efficiently storing and accessing all that information during inference is a major computational and memory challenge, especially for deployments on resource-constrained hardware like edge devices or mobile phones.
How does Paged Attention work?
The core idea behind Paged Attention is to partition the KV cache of each sequence into smaller, more manageable "pages" or blocks. Each block contains key-value vectors for a fixed number of tokens. This way, the KV cache can be loaded and accessed more efficiently during attention computation.
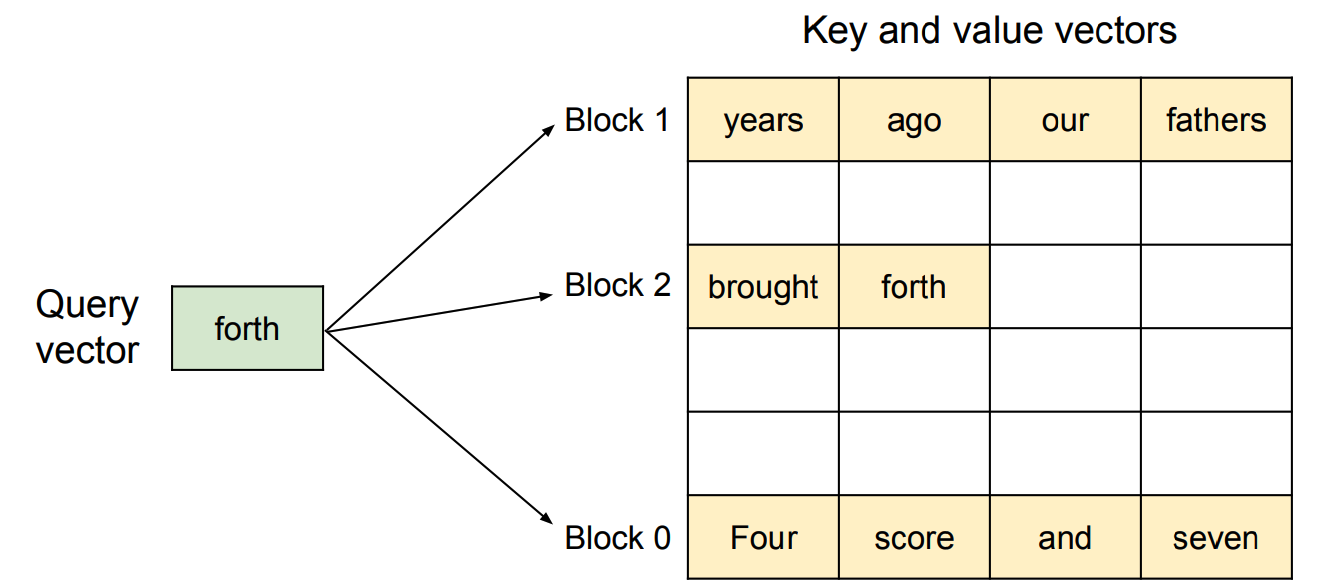
Figure 1: Illustration of how PagedAttention stores the attention key and values vectors as non-contiguous blocks in the memory (from the paper mentioned previously)
PagedAttention's approach to managing the memory used for storing key and value vectors is similar to how operating systems handle virtual memory. PagedAttention decouples the logical organization of the data from its physical storage. The logical blocks belonging to a sequence are mapped to potentially non-consecutive physical blocks using a block table. This abstraction allows for more flexible memory utilization, as new physical blocks can be allocated when new tokens are being generated.
The high-level process of the PagedAttention approach is:
- Partitioning the KV cache: The KV cache is divided into fixed-size blocks or "pages". Each block contains a subset of the key-value pairs from the original cache.
- Building the lookup table: A lookup table that maps query keys to the specific page(s) where the corresponding values are stored is constructed and maintained. This table maps each possible query key to the specific page(s) where the corresponding values are stored. This enables fast allocation and retrieval.
- Selective loading: During inference, the model only loads the pages that are necessary to process the current input sequence. This reduces the overall memory footprint compared to loading the entire KV cache.
- Attention computation: With the relevant pages loaded, the model can then perform the attention computation as usual, accessing the key-value pairs from the loaded pages as needed.
How to use Paged Attention?
vLLM
Paged Attention is employed by vLLM, an open-source library for fast LLM inference and serving, developed at UC Berkeley.
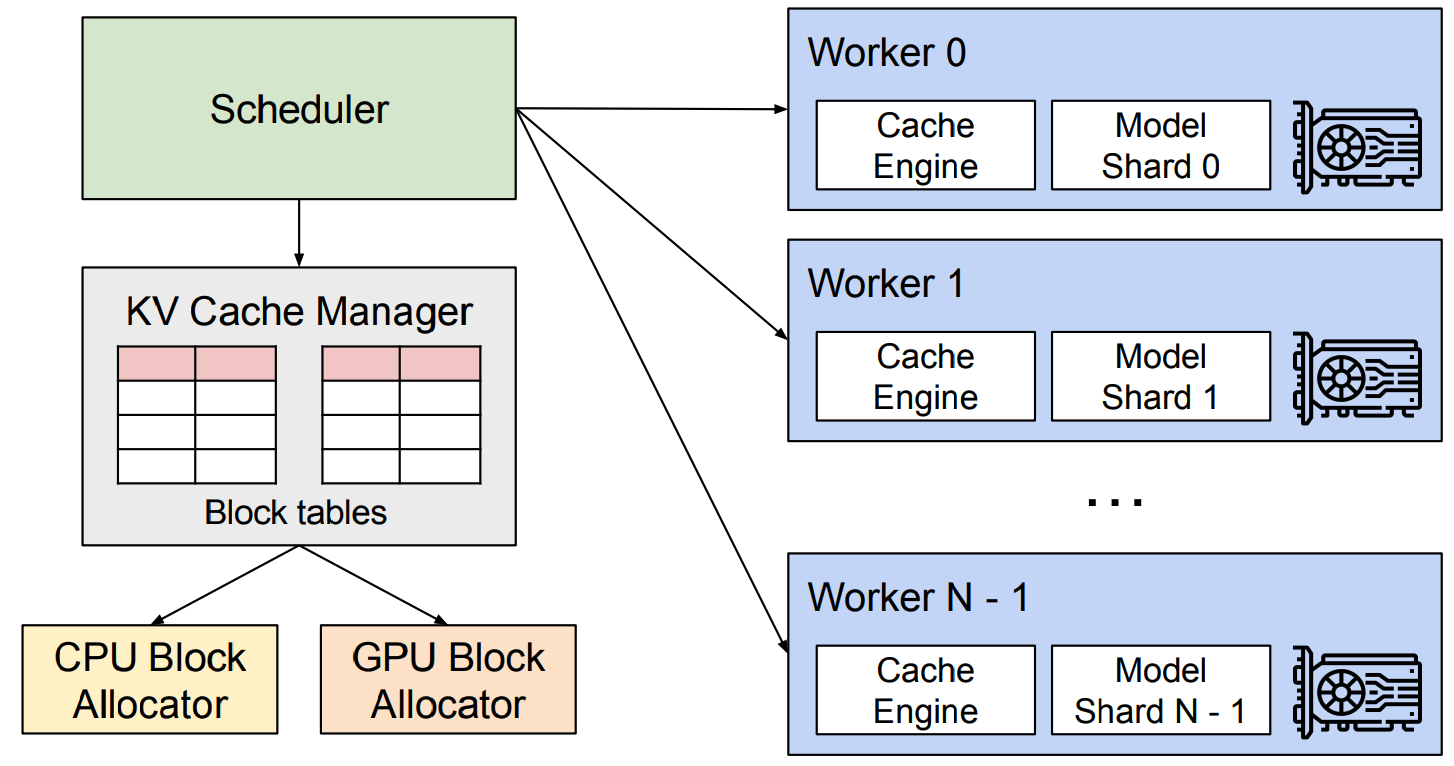
Figure 2: Overview of vLLM system (from the paper mentioned previously)
LMSYS has employed vLLM as a backend in their FastChat which powers Chatbot Arena to support the growing demands. LMSYS shows that the vLLM with the PagedAttention technique can improve the throughput up to 30x higher compared to one of their initial HF backend.
To use PagedAttention, one can use via vLLM. It can be installed via the following pip command.
vLLM supports both online serving and offline inference, which can be used directly in Python script through their Python library. The details can be found in the documentation.
What are the Benefits of PagedAttention?
The PagedAttention approach offers several key advantages that can make LLMs more memory-efficient and accessible.
Benefits:
- Near-optimal memory utilization: In PagedAttention, any memory waste is largely confined to the last block of an input sequence. This results in near-optimal memory usage, with only around a 4% waste on average. This substantial boost in memory efficiency enables the system to batch more sequences together, leading to higher GPU utilization and a significant increase in the overall throughput.
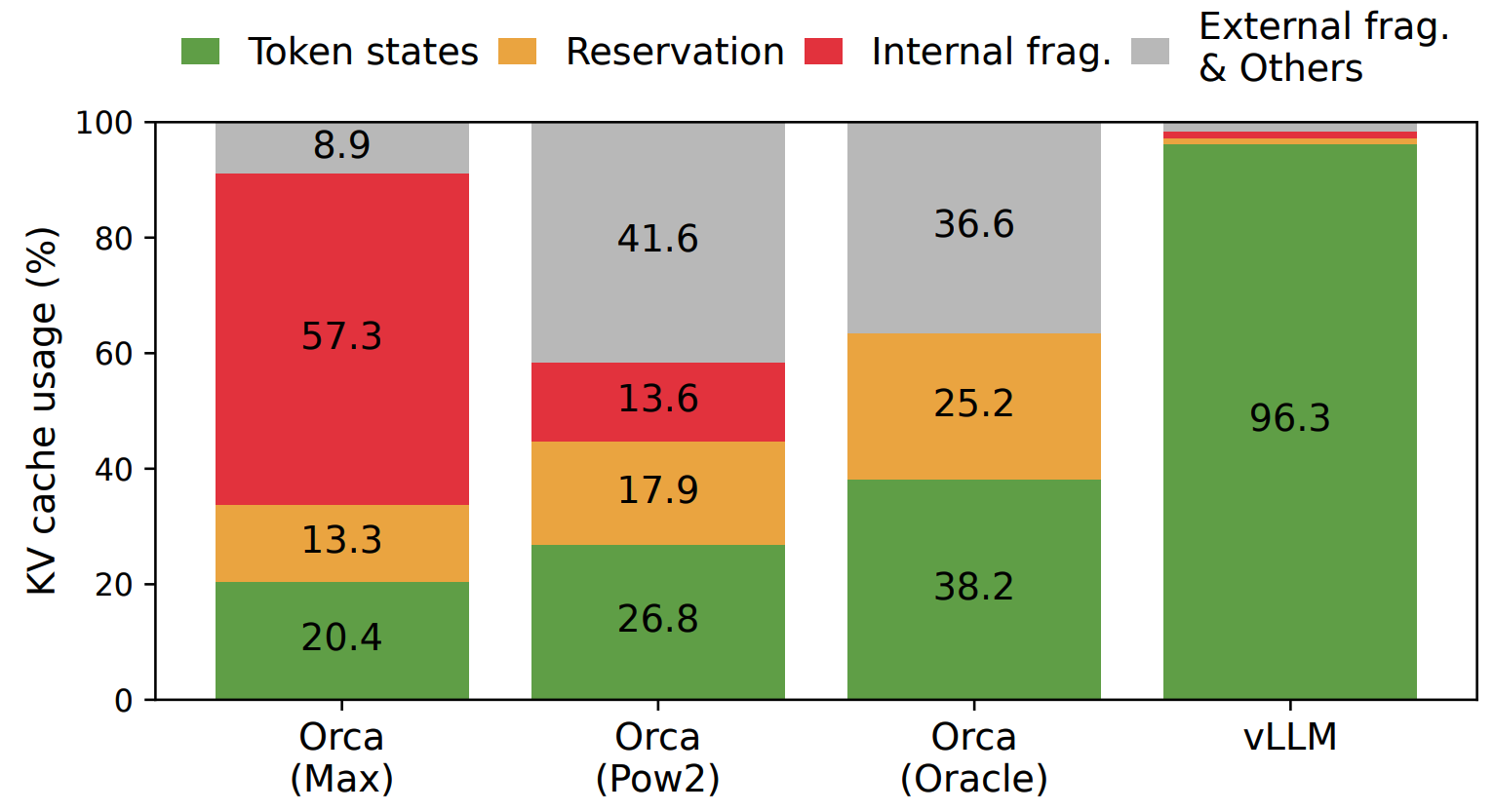
Figure 3: Illustration of the average memory wastes in different LLM serving systems. vLLM is the serving system using PagedAttention. (from the paper mentioned previously)
- Efficient memory sharing: When generating multiple output sequences from the same input prompt, the model can reuse the same cached KV pages across the parallel generations, avoiding redundant computation and memory usage. To ensure safe sharing, PagedAttention keeps track of the reference counts of the physical blocks and implements the Copy-on-Write mechanism. This memory sharing greatly reduces the memory overhead of complex sampling algorithms, such as parallel sampling and beam search, making advanced sampling methods more practical to deploy in LLM services.
- Reduced memory footprint: By partitioning the KV cache into smaller pages and only loading the necessary pages during inference, PagedAttention can drastically reduce the overall memory requirements of the LLM. This opens up the possibility of deploying and serving these powerful models on hardware with more limited memory resources.
- Potential for compression: The paged structure of the KV cache also opens up opportunities for further compression techniques. Individual pages could be compressed using various methods, reducing their memory footprint even further without significantly impacting the model's performance.
What are the potential Challenges of PagedAttention?
While PagedAttention offers many benefits, there are also some potential challenges and limitations to consider.
Challenges:
- Overhead of lookup table: The lookup table used to map query keys to KV cache pages adds some computational overhead during inference. The model needs to perform this lookup before it can load the relevant pages, which could impact inference speed if not implemented efficiently.
- Potential latency: Depending on the specific implementation and the size of the pages, there may be some latency introduced. For example, if the pages are too small, the frequent page loading and unloading could introduce latency.
- Generalization to other model architectures: While PagedAttention was initially developed for transformer-based LLMs, its applicability to other model architectures, such as recurrent neural networks or convolutional models, may require further research and adaptation.
Summary
In conclusion, PagedAttention is an innovative technique that addresses the significant memory challenges faced by serving LLMs. By partitioning the KV cache into smaller, more manageable pages and leveraging a lookup table for efficient access, PagedAttention can dramatically reduce the memory footprint of these powerful models, paving the way for their wider adoption and deployment in a variety of real-world applications.