Monolithic Machine Learning Pipeline
What is a monolithic ML pipeline?
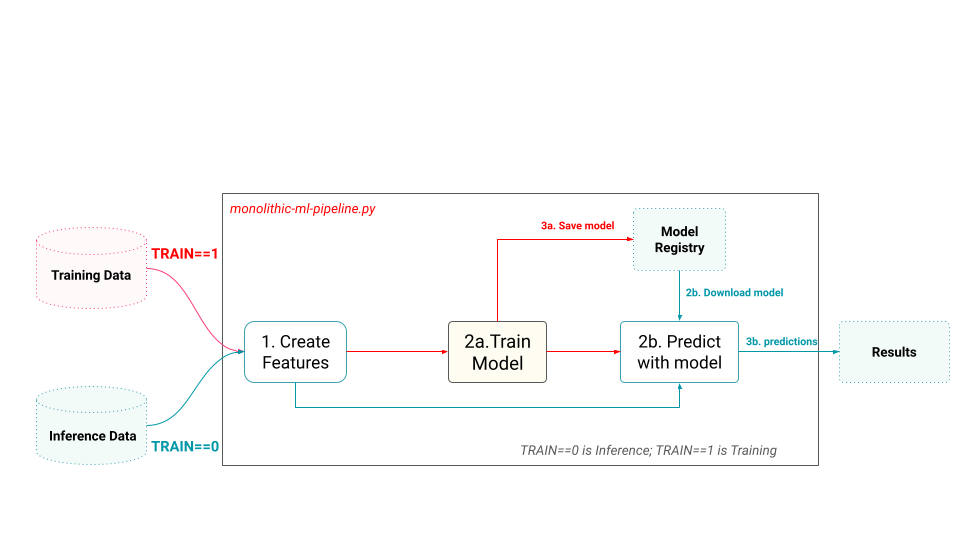
A monolithic ML pipeline is a single program that can be run as either (1) a feature pipeline followed by a training pipeline or (2) a feature pipeline followed by a batch inference pipeline. The monolithic ML pipeline is typically parameterized to run in either TRAIN mode or INFERENCE mode. Training mode takes historical raw data, computes features from it, trains the model and then saves the model to a model registry. Inference mode takes inference data, computes features from it (using the same feature logic as in training mode), downloads the model from the model registry, and makes predictions on the input features, with the results output to some storage sink.
Monolithic ML pipelines are only possible for batch ML systems, as online systems will need a separate online inference pipeline. Their advantage over separate feature/training/inference pipelines is that there is no need for a feature store, but the disadvantage is that materialized features cannot be reused across different models. Monolithic ML pipelines are also larger, more monolithic, systems that are harder to maintain and develop.